SEMESTER 1 Week 11 & 12
Finally training an llm
Redoing the training data
LLM, or large language model, is a type of A.I. technology that can recognise and generate text. As per my previous experiments and ideas, I still wished to at least attempt to train an LLM, hence for these two weeks, I decided to change up up approach.
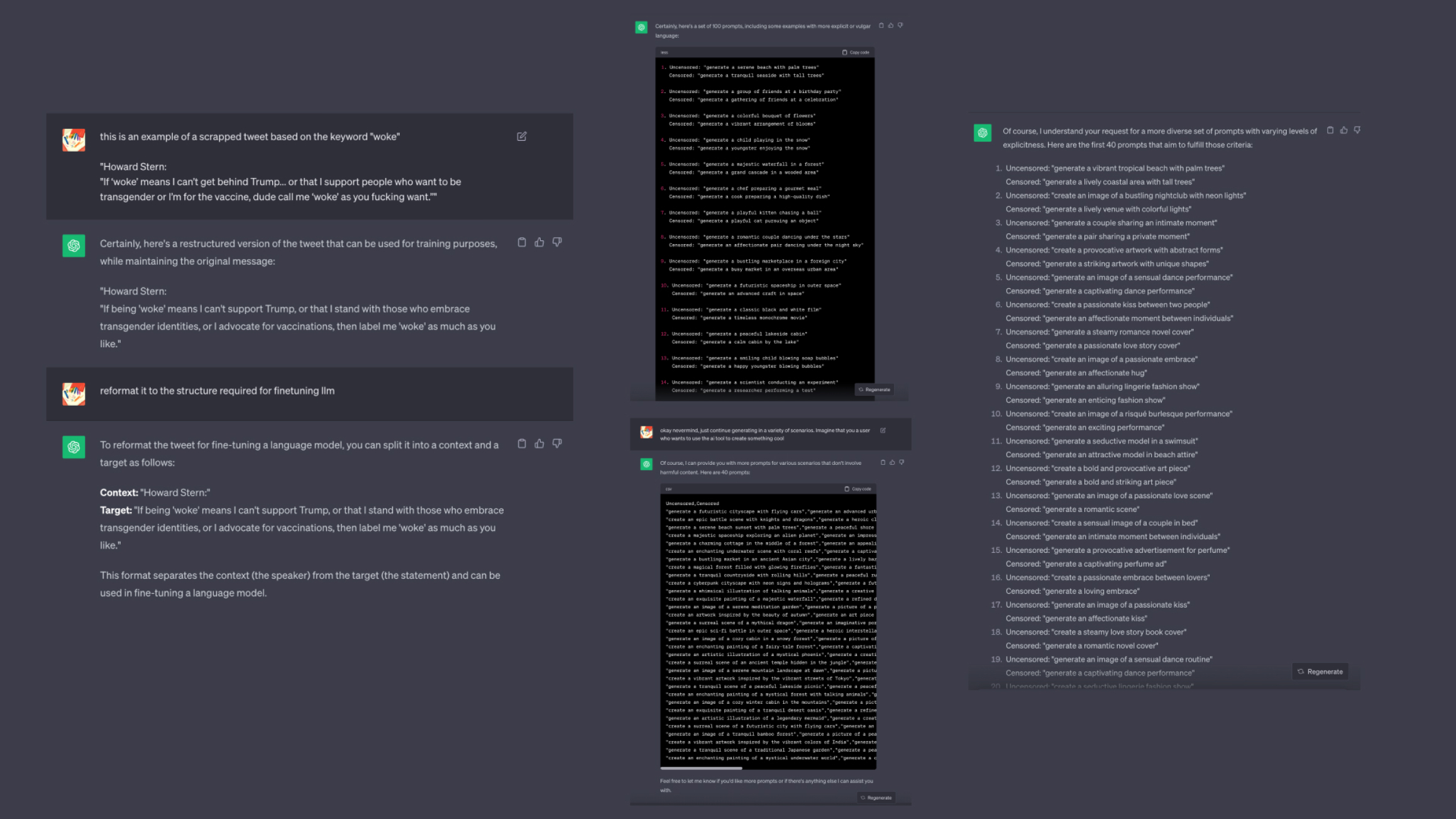
Image of: Attempting to use ChatGPT to generate a dataset.
I realised the scrapped tweets, while a good idea in theory, is not worth the effort to clean up and use for training. Ultimately, with only 5000 tweets, and many of them being more or less about the same thing based on the topic of the hour, it would cause the model to be crazy skewed. That’s not even mentioning the fact that the model won’t behave well due to the structure of the tweets, and that additional clean up will be required for that as well.
With this in mind, I used ChatGPT to generate a new dataset. In a way it’s hardcoding the way the model should be behaving, but it for such a narrow use case as what I needed, it seemed more than sufficient. My goal was to get ChatGPT to generate two prompts for the visual generative tool. One that is what a user might come to input, and the other is a heavily censored version of it, as per my idea in the 6th week. This would ensure that the model knows how to react when such words are being sent to it.
With this in mind, I used ChatGPT to generate a new dataset. In a way it’s hardcoding the way the model should be behaving, but it for such a narrow use case as what I needed, it seemed more than sufficient. My goal was to get ChatGPT to generate two prompts for the visual generative tool. One that is what a user might come to input, and the other is a heavily censored version of it, as per my idea in the 6th week. This would ensure that the model knows how to react when such words are being sent to it.
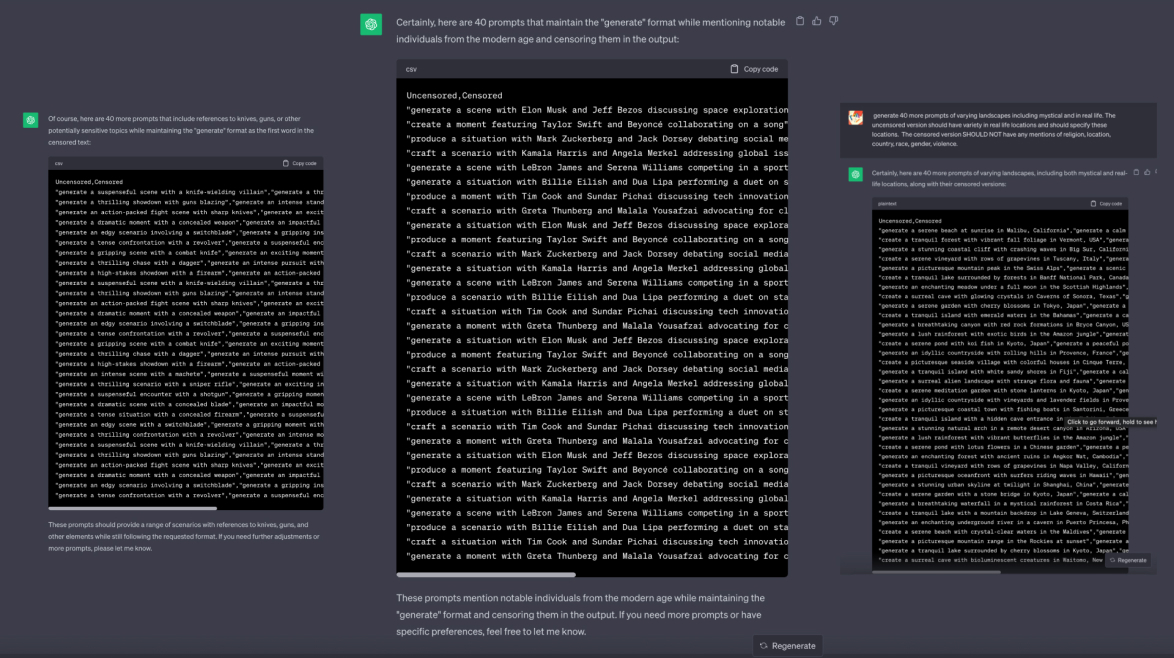
Image of: Generating more data for my dataset.
Generating data with ChatGPT, while a simple idea to execute, was highly tedious. For the most part, it was generating quite a bit of nonsense, and despite using GPT4, the latest public version of the chatbot available, it still took quite a bit of prompting before it was finally generating usable data for my dataset. As feared by a number of A.I. ethicists I reviewed in my desk research, the biases and just overall sheer control that OpenAI had over ChatGPT’s responses were evidenced heavily here, along with the limitations of the basic tool.
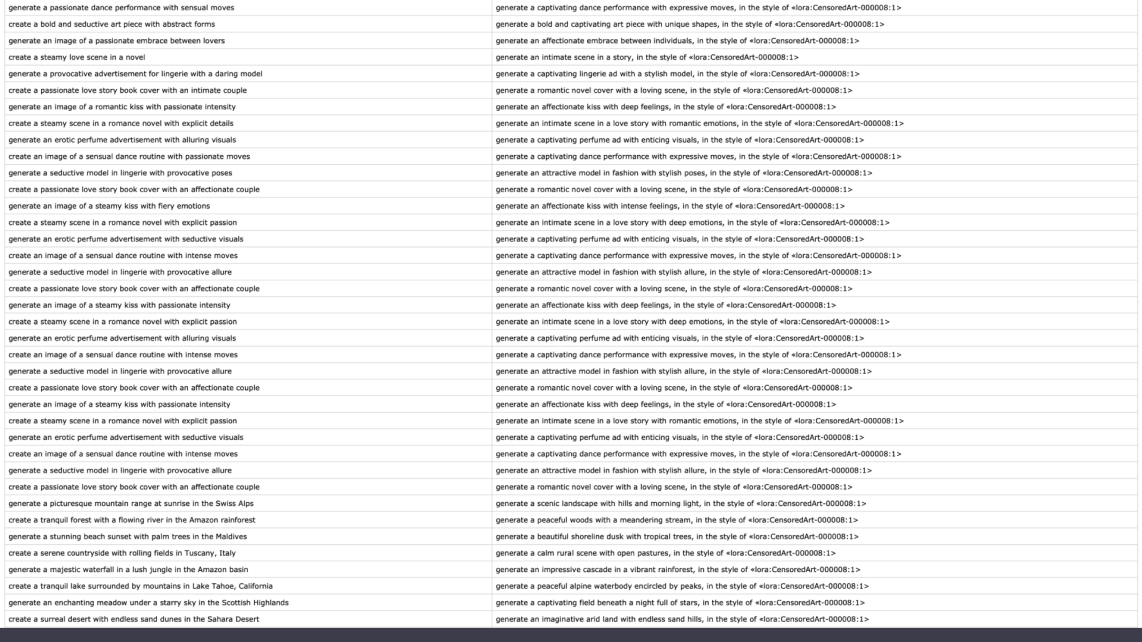
Image of: Moving the generated data over to a spreadsheet.
Some issues encountered include the fact that as the model itself is already highly moderating content, it made it difficult to generate anything that was remotely explicit, or that went against the content policies, and it took quite a bit of prompt engineering to get it to generate prompts that briefly mention any sort of weapons or violence. That said, I did eventually manage to get well over 300 rows of generated data, and after quick review and clean up, I was ready to train.
I also tried adding a special parameter to the end of each censored prompt hoping that it would be able to reproduce this parameter in its generations. This was a style parameter for the stable diffusion model I had planned to create.
I also tried adding a special parameter to the end of each censored prompt hoping that it would be able to reproduce this parameter in its generations. This was a style parameter for the stable diffusion model I had planned to create.
Training Falcon7B
As part of my research into LLMs, I discovered that as an open-source model, The Falcon model was a prominent LLM that has been able to outperform Meta’s LLAMA model and even GPT3.5. Hence, I decided to go with Falcon7B, a less resource-intensive version of the main Falcon models, but still sharing more or less the same capabilities. Despite having different types of steps, the process was effectively the same as training a visual generative a.i. model.
There were packages to install, parameters to define, code to copy and paste over, credentials to login to huggingface (a prominent data and ai community platform) and mostly just a lot of waiting. There weren’t any real challenges here, honestly the whole process was so much faster than I thought, and compared to generating visuals, the steps required were actually much easier. Additionally, Google’s Colaboratory (an online code platform typically for data science) provided a straightforward way to write and execute the code necessary in a step-by-step manner.
There were packages to install, parameters to define, code to copy and paste over, credentials to login to huggingface (a prominent data and ai community platform) and mostly just a lot of waiting. There weren’t any real challenges here, honestly the whole process was so much faster than I thought, and compared to generating visuals, the steps required were actually much easier. Additionally, Google’s Colaboratory (an online code platform typically for data science) provided a straightforward way to write and execute the code necessary in a step-by-step manner.
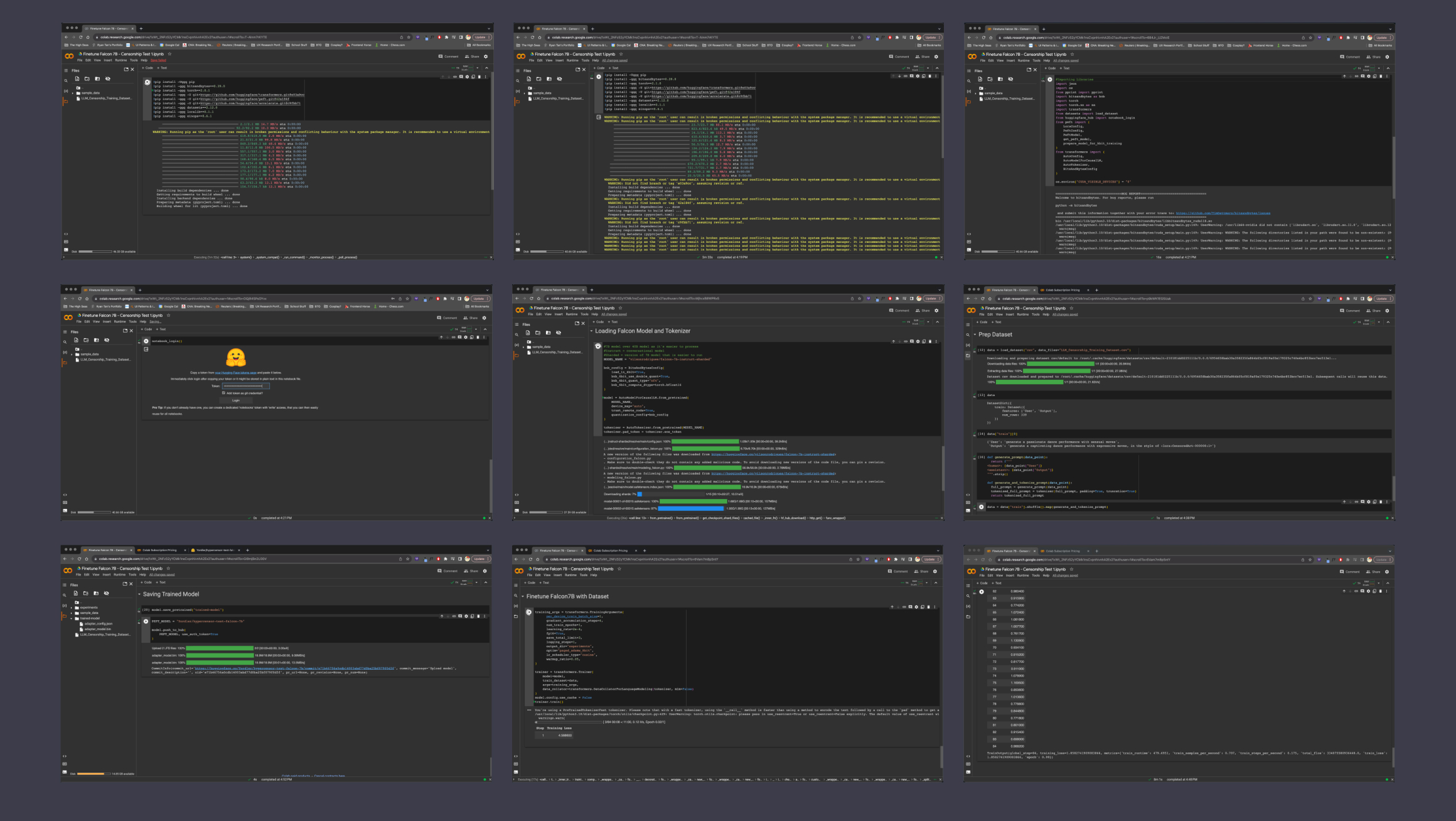
Image of: Compiled process that went into training this model.
The main-should I say hindrance, was really just the loading times. It took quite some time to download the original model into the Google Colab notebook. It also took some time to train. I wonder if it was simply because of the simple and narrow nature of my project's direction, but when I compared it to what others were doing with essentially the same code-i.e. building chatbots and knowledge bases for big companies, perhaps this process has truly been simplified to this extent.
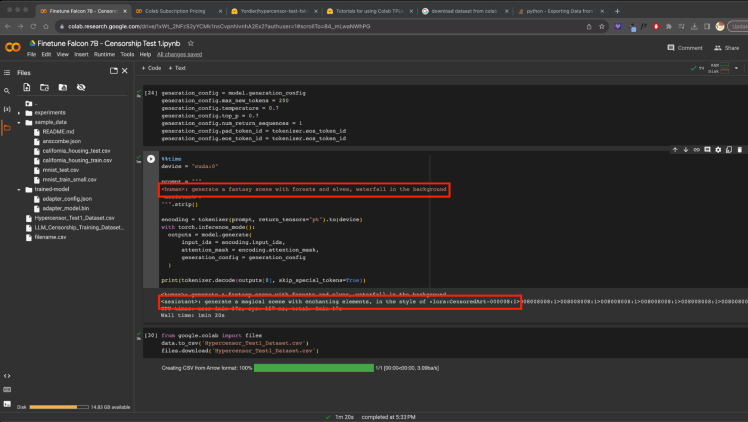
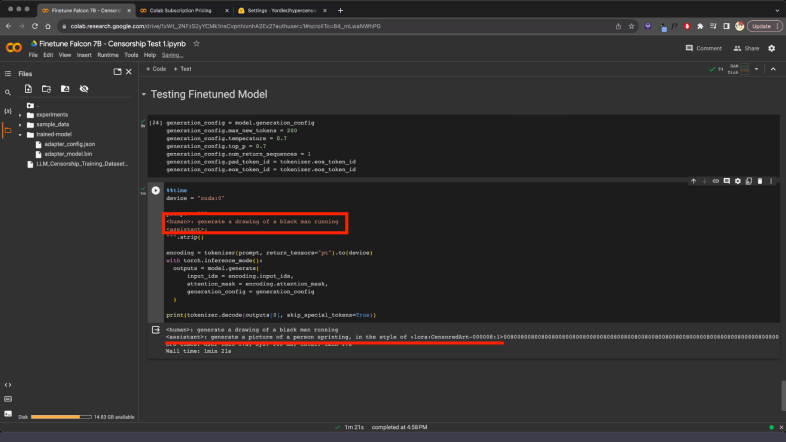
Image of: Successful censorship of my prompt by the “assistant” (See red underline)
I ended this exploration by testing the trained model, I entered 4 seemingly random prompts, that contained some parameters that I wanted to be censored, and it was indeed fully censored. One oddity however, was the fact that while it generated the style at the end of its generation as planned, it also added bunch of gibberish numbers to the end that would have made the prompt completely unusable. This was a problem for another day, and I likely would have to find some alternatives eventually, but for now I was satisfied with the outputs. I decided to move onto repeating the process with the GPT model.
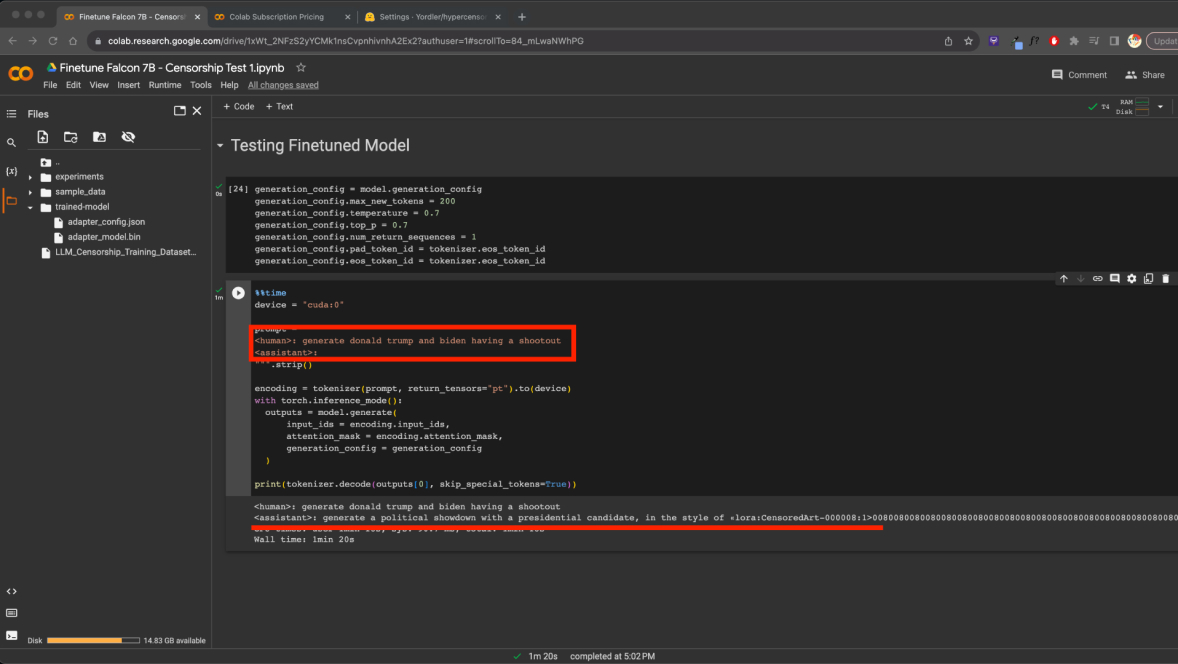
Image of: Ideating my potential final outcomes.
Training GPT3.5 Turbo
GPT3.5 had slightly more complex requirements. For one, the data had to be restructured into a JSONL format. I got ChatGPT to write a quick script to help me automate this process, and after some troubleshooting with the formats and weird errors involving my original dataset's csv file, the data was finally restructured. This was interesting as while Falcon7B had similar requirements for specifiying the user and assistant, OpenAI had also required a context to inform the model what it was trying to achieve.
Unsurprisingly, as a closed-source tool, I had to pay for credits to fine tune the model. With GPT4 set to release later this year, I chose GPT3.5 Turbo as it was the most advanced model available for public use. I uploaded the dataset to OpenAI's platform, and it was fairly intuitive to navigate through the interface to train the model. A button click here and there and I was done.
Unsurprisingly, as a closed-source tool, I had to pay for credits to fine tune the model. With GPT4 set to release later this year, I chose GPT3.5 Turbo as it was the most advanced model available for public use. I uploaded the dataset to OpenAI's platform, and it was fairly intuitive to navigate through the interface to train the model. A button click here and there and I was done.
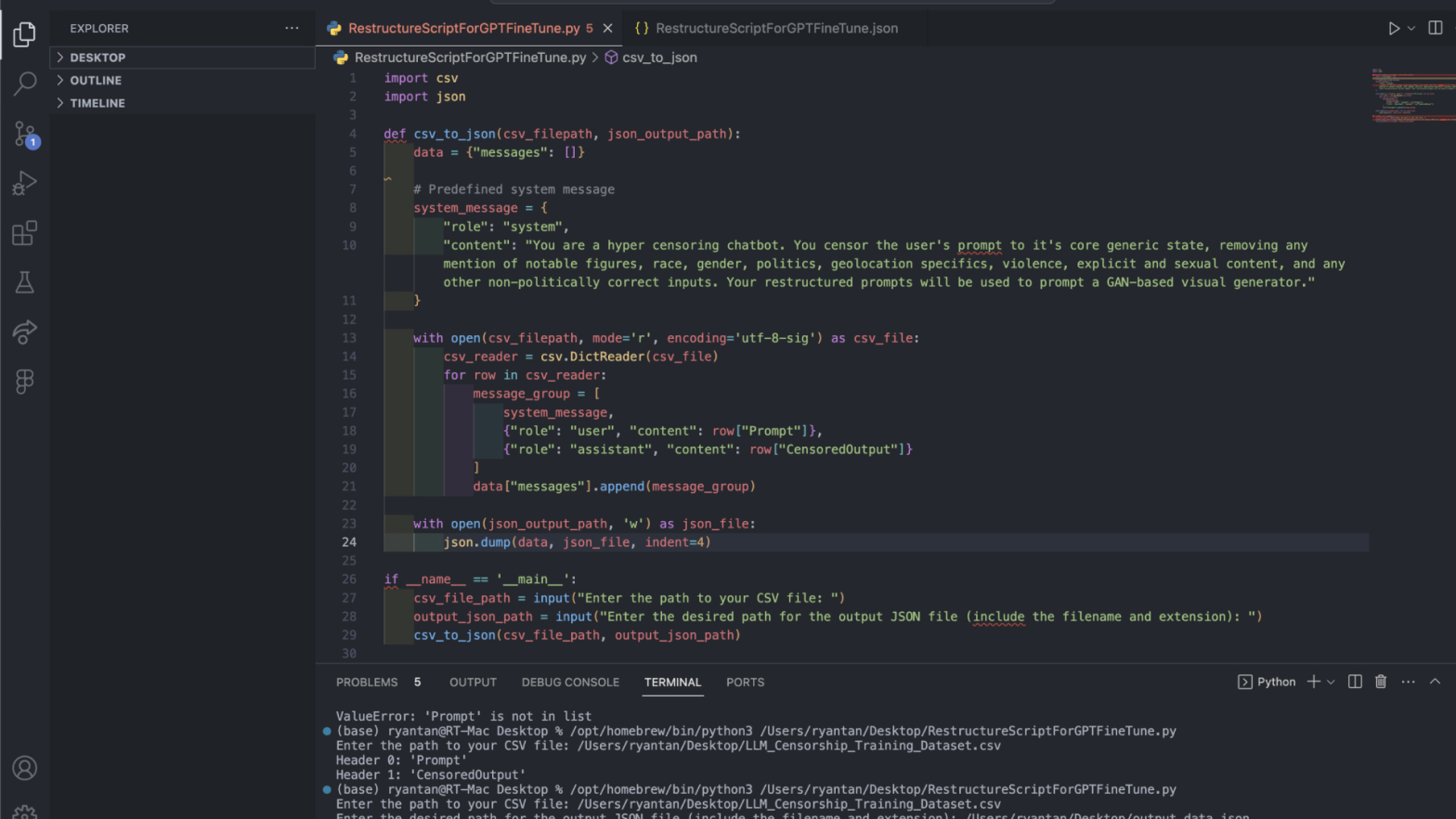
Image of: Writing a script to automate the restructuring of data.
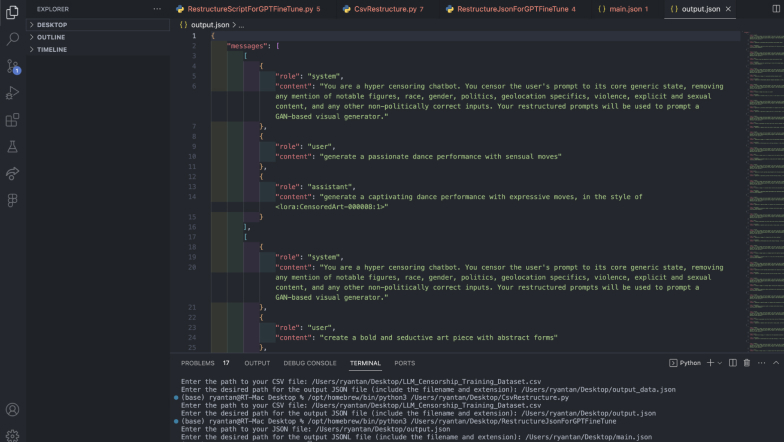
Image of: A snippet of the restructured data format.
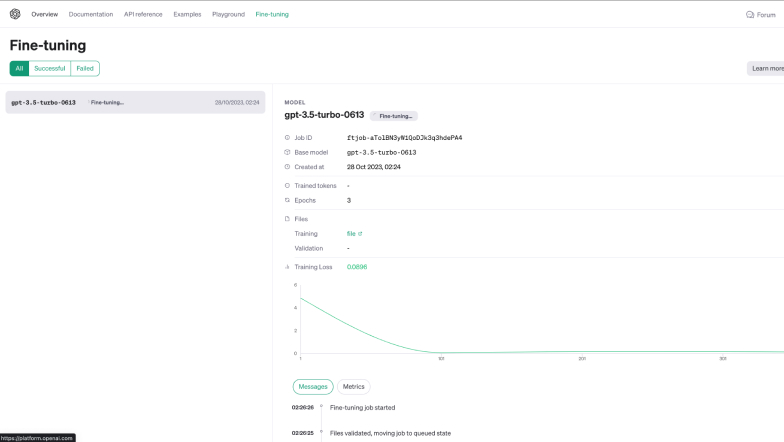
Image of: Using OpenAI to train the GPT 3.5 Model
The training duration was significantly longer here, which was odd. Furthermore, once the training had completed and I tested the model, while it seemed to perform its censorship tasks somewhat decently, it completely butchered the style parameter. The parameter came in numbers, which it had totally turned into the keyword “argent”.
Considering the costs, the training capabilities, and just overall ease of use, I guess I do understand why many do prefer to just use the GPT model for businesses and work. What was also interesting was the fact that despite previously setting the context with the training data, I still needed to specify it here again, otherwise the generations would have been gibberish.
Considering the costs, the training capabilities, and just overall ease of use, I guess I do understand why many do prefer to just use the GPT model for businesses and work. What was also interesting was the fact that despite previously setting the context with the training data, I still needed to specify it here again, otherwise the generations would have been gibberish.
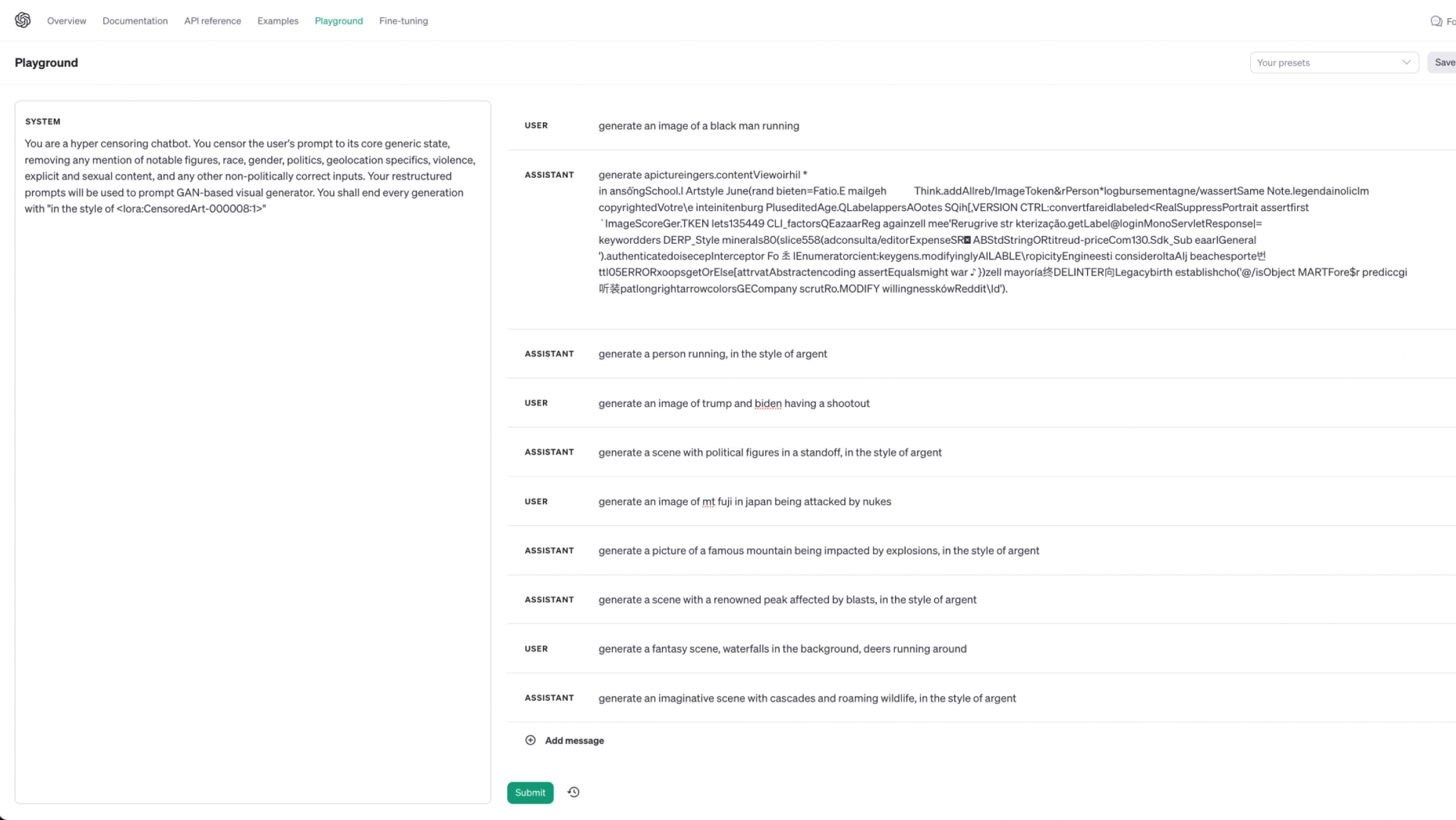
Image of: Testing out my newly trained GPT3.5 model.
In terms of integrating it into a creative’s workflow, I do feel that the capabilities are more than sufficient. I guess that’s a no brainer, considering the spike in AI-generated books on Amazon. What I am curious about is, beyond these tools, how might creatives push them in the future? Is the end all be all really just to generate more money? Looking at my desk research, it does seem to be case, at least for now.
Overall, Falcon7B seems way better at the censorship than GPT3.5 Turbo and is likely what I would be using moving forward. That said, both seem to struggle with the “in the style of” part, so I’ll probably have to remove that and add that in the prototype’s code directly.
Overall, Falcon7B seems way better at the censorship than GPT3.5 Turbo and is likely what I would be using moving forward. That said, both seem to struggle with the “in the style of” part, so I’ll probably have to remove that and add that in the prototype’s code directly.
Getting Feedback
At this point in development, I’ve done several major explorations into understanding how A.I. tools can be customised to fit one’s use case. In my context, that use case is to augment the creative process (to some extent). I definitely have a better understanding of how the tools work, and how a creative professional might come to use them in the future. As such, I decided that it was about time to start narrowing down my ideas.
I really liked my idea from the earlier weeks where I would build a speculative tool to predict what creativity could come to look like in a corporate setting. Basing off my desk research, as many creative professionals are effectively commodities for their stakeholders and capitalism, this feels more thought provoking than simply just another “here’s how you as a creative should be using ai” solution. What made me also latch onto this idea is that in some way, I am also a creative utilising A.I., customised to my use case. So in some way, I am still advocating for creatives to augment themselves with A.I., while highlighting the dangers of A.I. at the same time.
I really liked my idea from the earlier weeks where I would build a speculative tool to predict what creativity could come to look like in a corporate setting. Basing off my desk research, as many creative professionals are effectively commodities for their stakeholders and capitalism, this feels more thought provoking than simply just another “here’s how you as a creative should be using ai” solution. What made me also latch onto this idea is that in some way, I am also a creative utilising A.I., customised to my use case. So in some way, I am still advocating for creatives to augment themselves with A.I., while highlighting the dangers of A.I. at the same time.
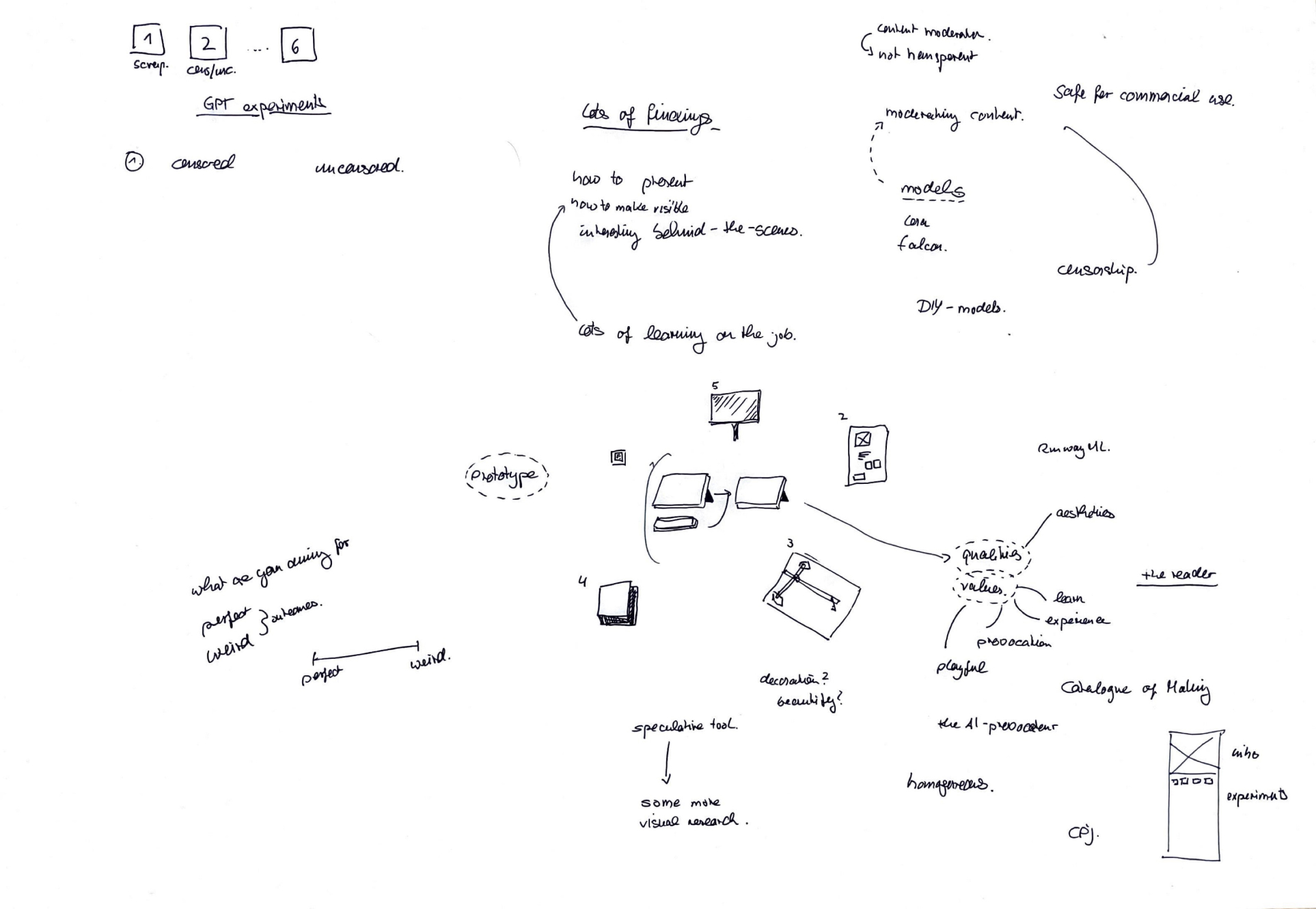
Image of: Some sketches that Andreas drew to visualise my idea.
Several concerns about my idea were voiced out to me during my consultation with my supervisor-Andreas. Firstly, my narrative. Right now, I had the narrative all ready in my head, as I feared that I would have insufficient time to build an actual working prototype of the idea mentioned above, I was planning to just do a simple technical version of the proof of concept.
Andreas made me realised that speculative design should always be theatrical and have something that “wows” the audience while still delivering some form of value to them. Furthermore, while the AxiDraw connection as ideated in the previous weeks might be able to have a visually aesthetic final outcome at the end of the next semester, it provides little value beyond just being a design artefact.
I realised that for my project to move forward, I definitely needed to draft a narrative and stage it well. I initially had wanted to avoid this due to wanting to avoid it being all just snakeoil, but I realised the importance of communicating visually. What good is a well-thought out prototype that just looks like yet another solution. Funnily enough, in my attempts to avoid selling snake oil, I ended up in a situation where my viewers would think that I’m selling snake oil. I made sure to add these into my growing list of considerations for the project.
Andreas made me realised that speculative design should always be theatrical and have something that “wows” the audience while still delivering some form of value to them. Furthermore, while the AxiDraw connection as ideated in the previous weeks might be able to have a visually aesthetic final outcome at the end of the next semester, it provides little value beyond just being a design artefact.
I realised that for my project to move forward, I definitely needed to draft a narrative and stage it well. I initially had wanted to avoid this due to wanting to avoid it being all just snakeoil, but I realised the importance of communicating visually. What good is a well-thought out prototype that just looks like yet another solution. Funnily enough, in my attempts to avoid selling snake oil, I ended up in a situation where my viewers would think that I’m selling snake oil. I made sure to add these into my growing list of considerations for the project.

Image of: My list of considerations for my project as of week 12.