SEMESTER 1 Week 7 & 8
What Do I Do With These?
Tackling the text dataset
With the research proposal outline completed, I returned to this chunk of data that I now had lying in front of me. I realised I didn’t actually know how to sift through, and clean up this 6000+ rows of scrapped data. Let alone actually use it for A.I. training.
Image of: Trying to understand how to analyse data
I looked through several tutorials and following their instructions, I was able to build a series of data analysis scripts using python that would read the data and organise it for me. While this in itself was a fairly straightforward exercise, I was for the most part just blindly following the instructions and could not really understand what I was doing.
The following images below cover the process of trying to figure out how to clean up and work with the text data.
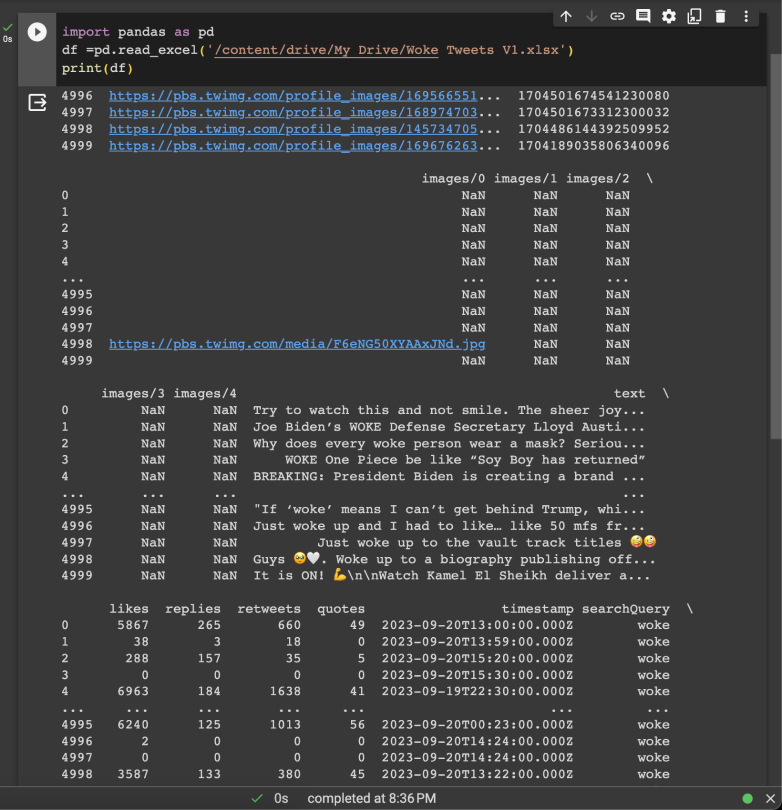
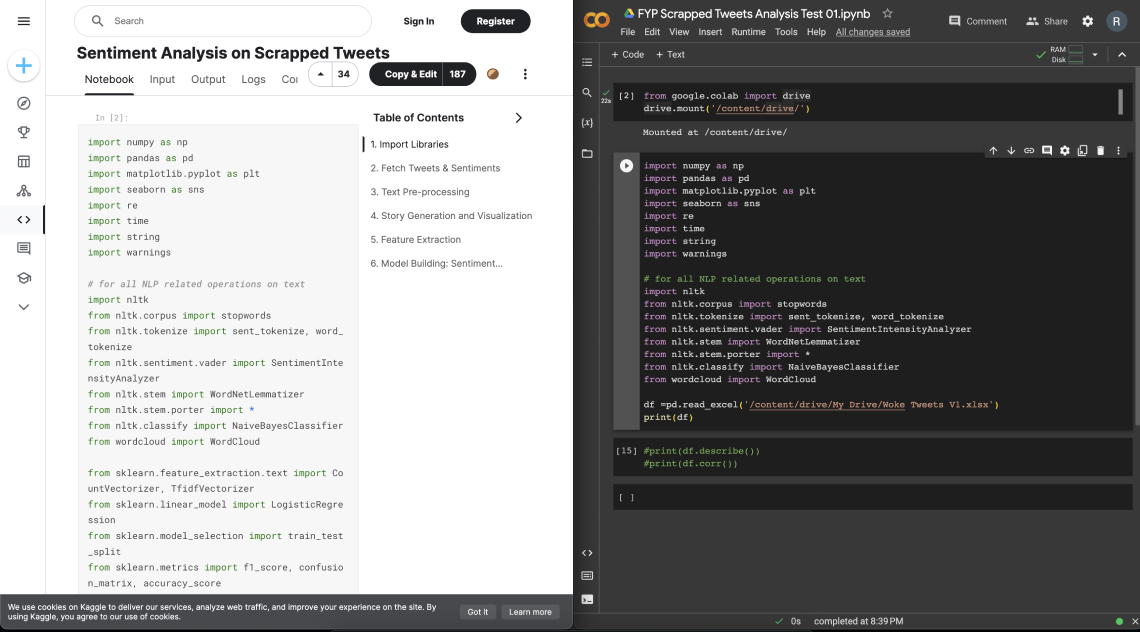
I eventually decided to call off this exploration after I performed the sentiment analysis on the tweets. Sentiment analysis is a technique used in data analysis to visualise and get an understanding of the data’s impressions of a specific topic.
In my case, the python library I had been using seemed to have classified tweets with negative and positive with opposite sentiments, which has led to extremely negative tweets such as calling for discrimination and action against vulnerable groups as “positive” tweets.
The tutorial I had been following made me generate all sorts of graphs using the imported data analysis libraries. While I can imagine that these are useful for some people, I genuinely could not draw the link between what I’m doing here and how the data would eventually be cleaned up to be used for training a large language model (text-based A.I.).
In my case, the python library I had been using seemed to have classified tweets with negative and positive with opposite sentiments, which has led to extremely negative tweets such as calling for discrimination and action against vulnerable groups as “positive” tweets.
The tutorial I had been following made me generate all sorts of graphs using the imported data analysis libraries. While I can imagine that these are useful for some people, I genuinely could not draw the link between what I’m doing here and how the data would eventually be cleaned up to be used for training a large language model (text-based A.I.).

Image of: The letter cloud mistake.
While this exercise was effectively a failure, it did demonstrate one of the biggest issues and considerations that come with big data and by extension, artificial intelligence that I had learnt from my desk research. I.e. Without proper and objective clean up, many of the tools are just a single step away from being harmful towards groups that have non-representational data. In my case, not only was the data tagged with incorrect sentiments, when I took a look at the spreadsheet, it seemed like more than half of the dataset was about people waking up rather than actual “woke” controversial tweets. I shudder to think about the A.I. model that gets trained on that data.
This is also very adamantly obvious in projects done by other ai artists like memo akten’s Learning to See, where a limited set of data can misclassify and misrepresent certain truths. At this point, I’m not too certain on what directions I can take my exploration, so this seemed like a good stopping point for the experiment.I rounded off the experiment with some word clouds based on the sentiment analysis conducted. It was definitely an interesting visual. It was also interesting when I initially messed up the code and it became a letter-cloud instead.
This is also very adamantly obvious in projects done by other ai artists like memo akten’s Learning to See, where a limited set of data can misclassify and misrepresent certain truths. At this point, I’m not too certain on what directions I can take my exploration, so this seemed like a good stopping point for the experiment.I rounded off the experiment with some word clouds based on the sentiment analysis conducted. It was definitely an interesting visual. It was also interesting when I initially messed up the code and it became a letter-cloud instead.

Image of: Words from tweets tagged with positive sentiments.