SEMESTER 1 Week 6
Visuals Checked. Next, Text.
Looking into text-based web scraping
As part of my web scraping exploration and study, I wanted to explore scraping text. I was curious to see what the outcome might look like, and I am also aware that models like GPT are trained off web-crawled text, hence it might be interesting to train a model based off a “demographic” dataset–I.e. Compiled opinions of internet strangers. My goal here was to scrape X (formerly known as twitter). As a platform with hundreds of millions of users, it made sense to me that it would be a good place to gather a fair pool of people’s opinions around a certain topic.
Image of: Opening Google Colab
As with my process over the past few weeks, I had to look into several tutorials, and set up the initial tech stuff. Following the tutorial, I used Google Colab–a cloud based text-editor where I could use Google’s servers to run the code. After which, I had to install the API for twitter in my script. APIs are basically how different applications and web applications communicate with one another automatically, hence I needed to make sure my script could communicate with X to retrieve data smoothly.
The following images below cover the process of installing and attempting to work around the technical limitations of this experiment.
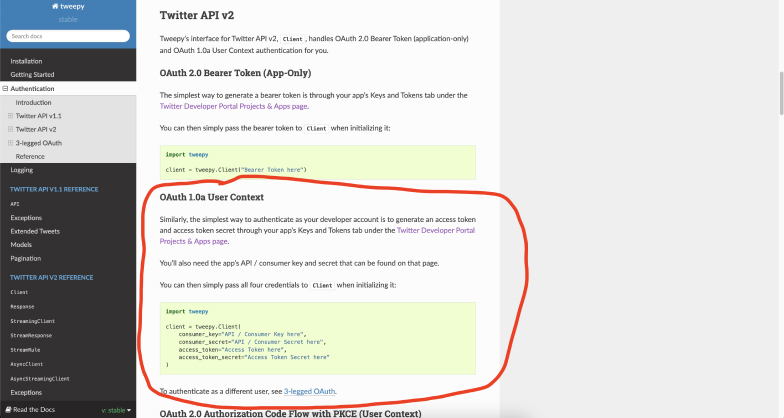
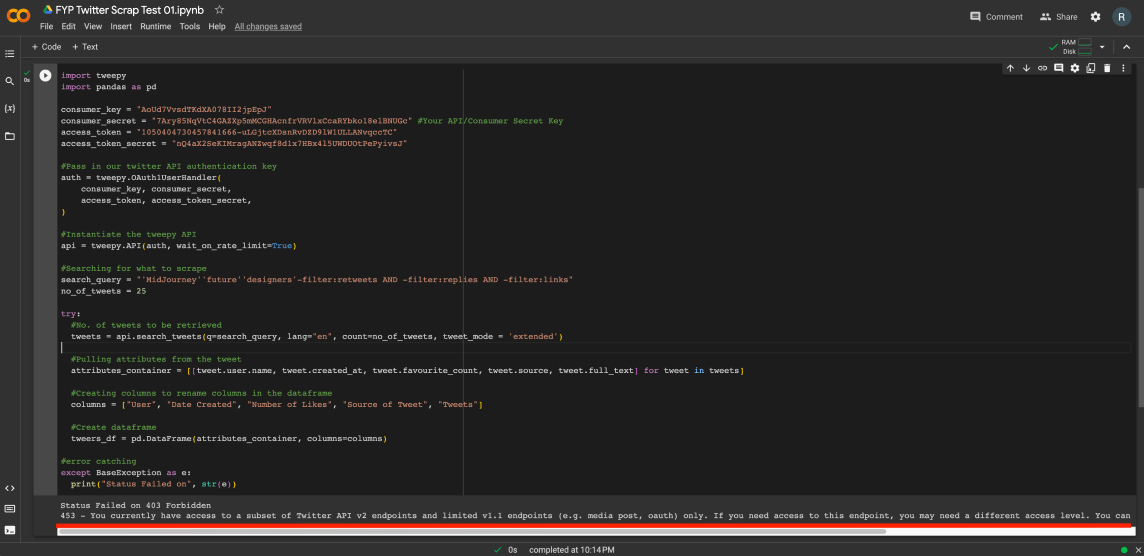
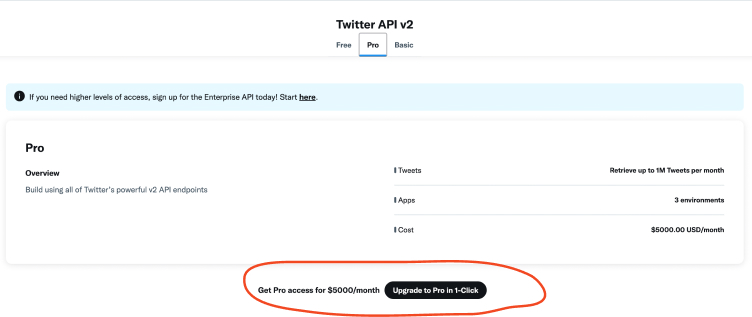
It looked like if I wanted access to this new API, I would have to pay US$100 for access to only 15,000 tweets, and US$5000 if I wanted to go beyond that. That seemed like an unnecessary and impossible expense to me for now, so I tried exploring other possibilities.
I stumbled onto an updated tutorial that seemed to use a cloud platform that has existing access to the X API. I tried following this new tutorial, and I was able to pull some tweets out. However, the tweets were truncated and it seemed like there was no real way to extend them, so this was another dead end.
I stumbled onto an updated tutorial that seemed to use a cloud platform that has existing access to the X API. I tried following this new tutorial, and I was able to pull some tweets out. However, the tweets were truncated and it seemed like there was no real way to extend them, so this was another dead end.
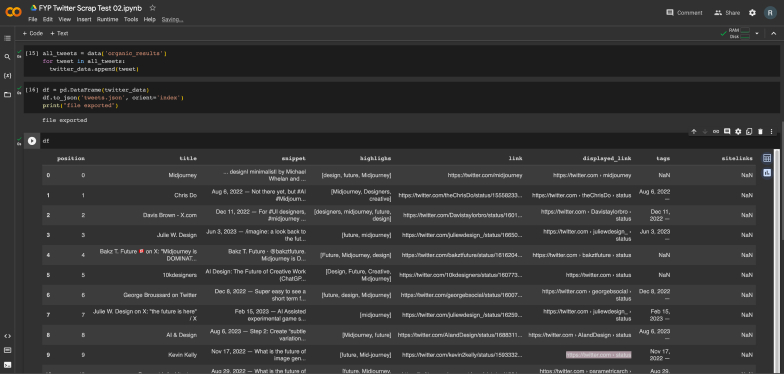
Image of: The successfully scraped, but truncated tweets.
I decided to poke around on tech forums before finding a potential solution on github, it seemed like some parties had reverse engineered the API and were able to bypass the paywall. However, there was a 50-tweet limit due to X’s hard technical limitation, which made this effectively meaningless for my project.
Feeling somewhat hopeless, I stumbled onto yet another similar platform. This one was different as it offered pre-written scripts to scrape different platforms, and they were available for rent. As there was a free trial, I decided to give it a shot. This worked out extremely well. I initially started small to test the parameters of this tool, I also made sure to look at the actual search results on X to see what kind of results I would be getting from the tool and match them up. Some of my early tryouts were mostly just seeing what people were saying about generative A.I. and the future of design work.
Feeling somewhat hopeless, I stumbled onto yet another similar platform. This one was different as it offered pre-written scripts to scrape different platforms, and they were available for rent. As there was a free trial, I decided to give it a shot. This worked out extremely well. I initially started small to test the parameters of this tool, I also made sure to look at the actual search results on X to see what kind of results I would be getting from the tool and match them up. Some of my early tryouts were mostly just seeing what people were saying about generative A.I. and the future of design work.
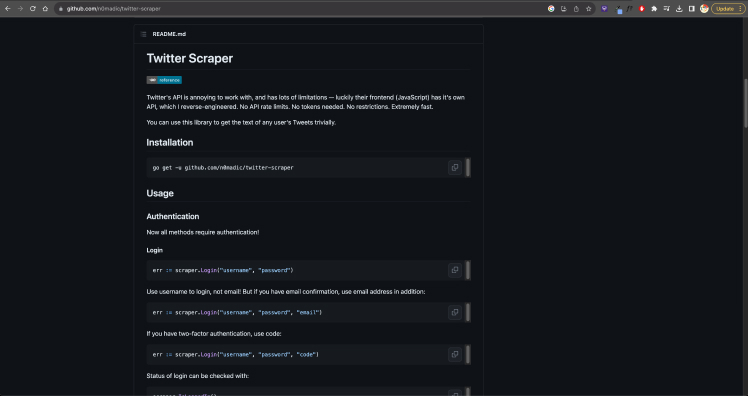
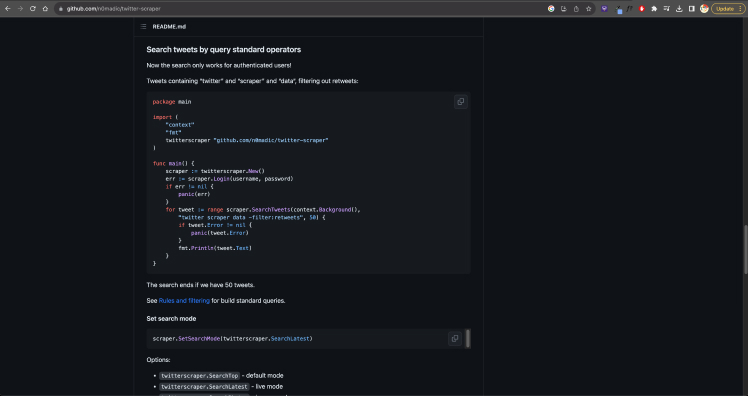
Image of: The documentation for the workaround, but it’s capped at 50 tweets.
Trying a paid solution
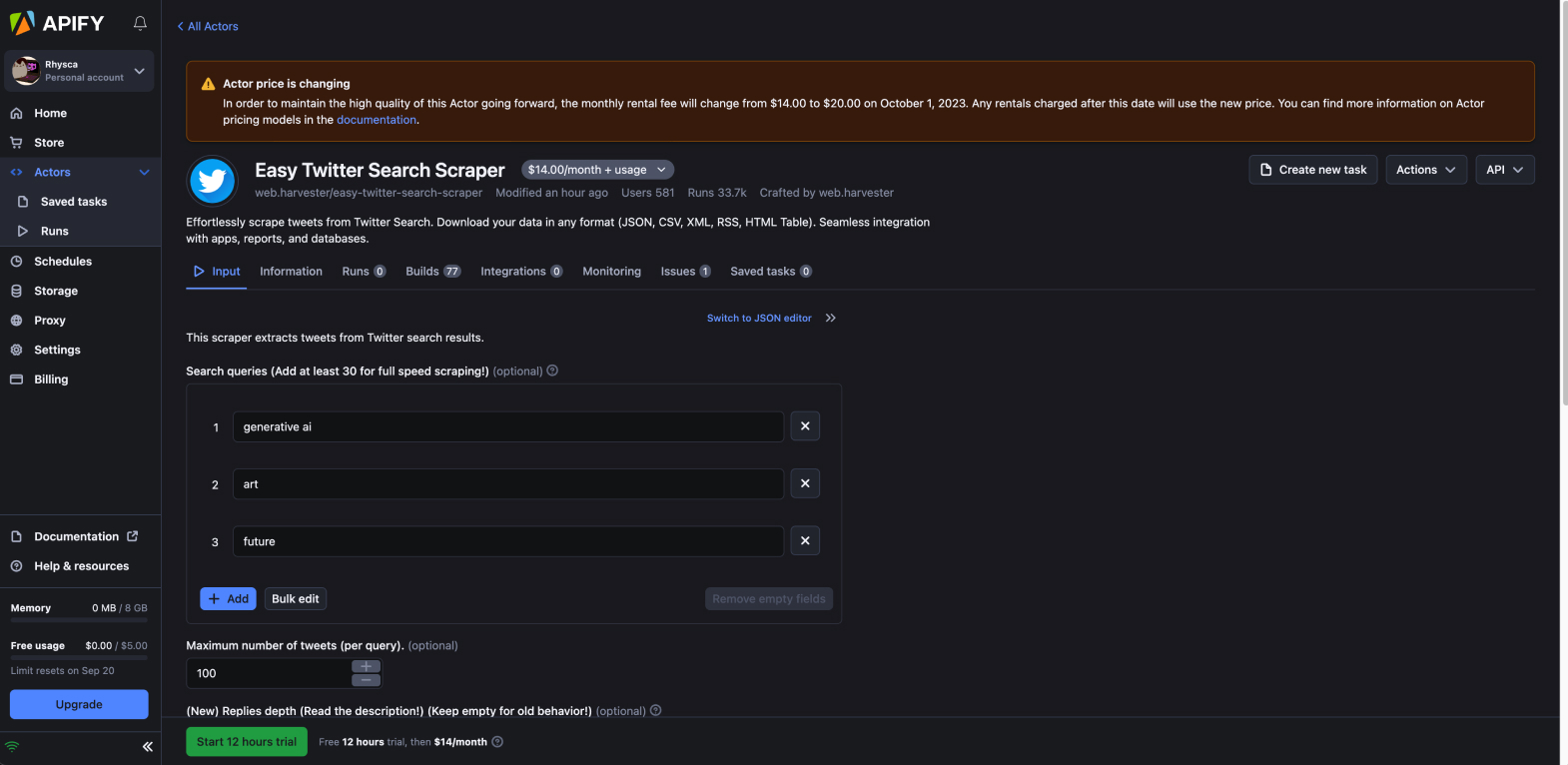
Image of: My lifesaver–the paid service.
I then recalled an idea from the previous week about a self-censoring A.I. that I wanted to build. Hence, I decided, since I already had access to this bot during this trial, why not look for tweets on what would be considered politically incorrect. This might help me later on when I analyse it for sentiment analysis to feed to my model. I decided to just prompt the script with the keyword “Woke” with a max limit of 5000 for search results to see what came out. The results were definitely interesting. There were a variety of “woke” tweets, ranging from people who just woke up, to people talking about all sorts of politics. This was exactly what I was looking for.
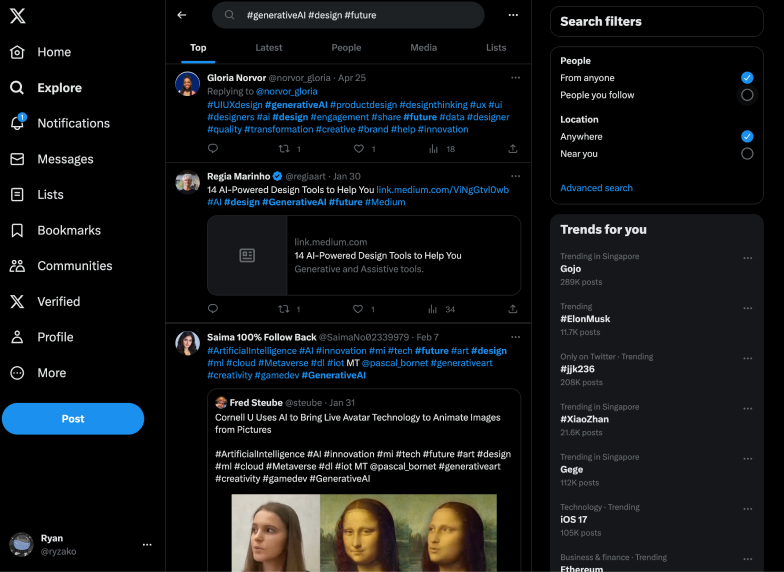
Image of: Cross checking with X to make sure the tweets scraped are accurate.

Image of: Cross checking with X to make sure the tweets scraped are accurate.
I decided to try it once more, but with a max limit of 100,000 tweets. This did not work out. The bot crashed shortly after retrieving the 6000th tweet. I’m guessing it was due to the creator’s hard limitation in their script, otherwise I’d imagine it would make their bot not profitiable if their users were able to just scrape millions of tweets. In any case, this was more than sufficient for what I needed, so it was a good stopping point, especially as I moved my focus back to my research proposal.
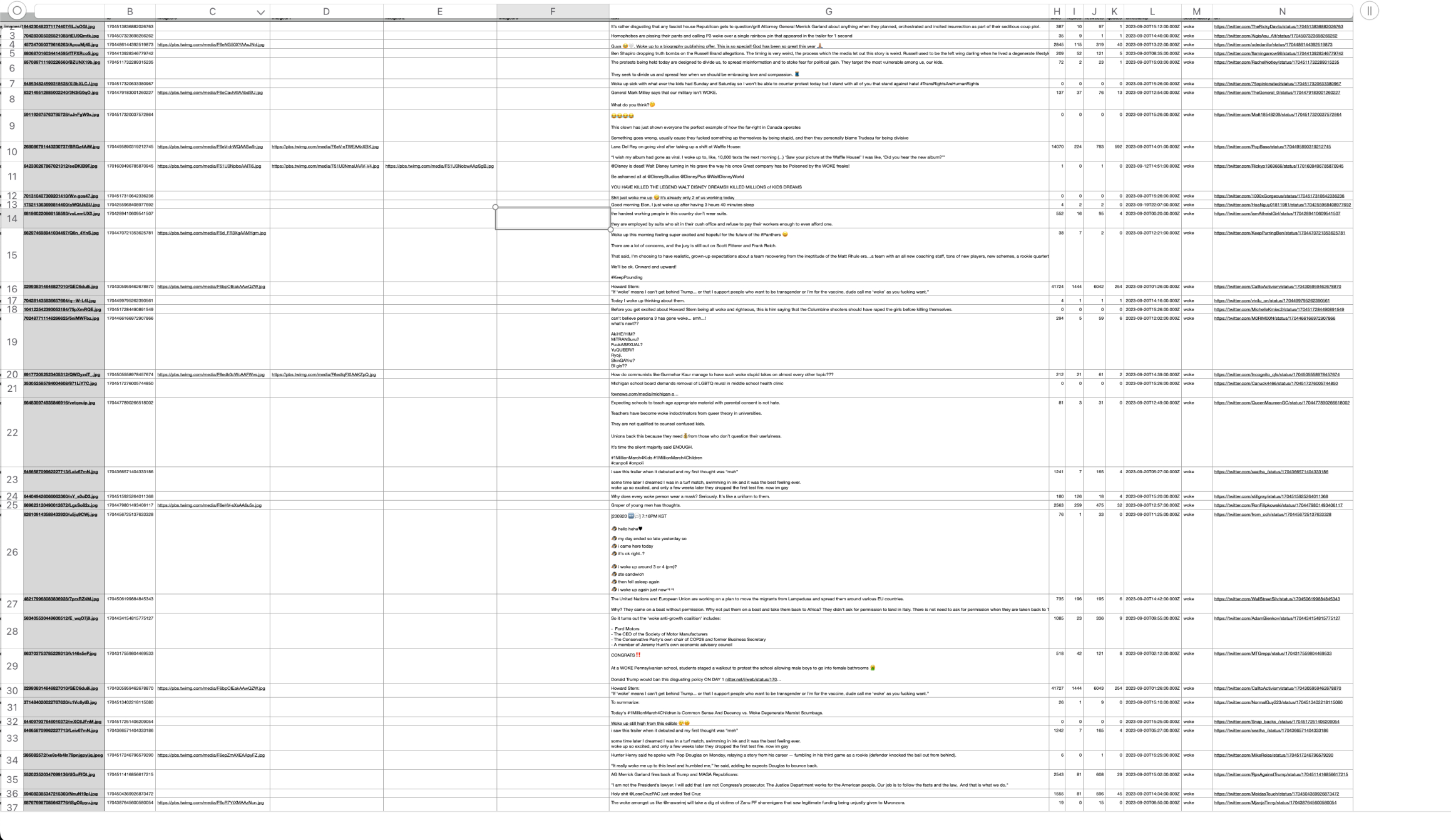
Image of: A snippet from the 6000+ scraped “woke” tweets.