SEMESTER 1 Week 2
Building Project Context

Image of: Me giving an introductory sharing about my project.
Atelier Sharing
As a means of bringing the Atelier up to speed on my project, and to also potentially further refine the scope of the project, we were tasked to give a short sharing on the current state of the project. I tentatively named the project, Generated Creativity.
The name did not have any real meaning, I just thought it suited the overall themes of the project which were generative AI and speculating the creative workforce. I constructed the sharing in Figma and made sure to cover important aspects of the project such as key statistics about how people currently feel about AI, as well as a brief history of AI itself.
My supervisor–Andreas, prompted me about what the name meant, and to ensure that the name wasn’t just arbitrary by the end. He urged me to think about what the current name could mean by thinking about what the keywords themselves could mean. I guess this could be a nice exercise for once I had finally settled on a name, but for now I left the placeholder title as is.
The name did not have any real meaning, I just thought it suited the overall themes of the project which were generative AI and speculating the creative workforce. I constructed the sharing in Figma and made sure to cover important aspects of the project such as key statistics about how people currently feel about AI, as well as a brief history of AI itself.
My supervisor–Andreas, prompted me about what the name meant, and to ensure that the name wasn’t just arbitrary by the end. He urged me to think about what the current name could mean by thinking about what the keywords themselves could mean. I guess this could be a nice exercise for once I had finally settled on a name, but for now I left the placeholder title as is.



Image Gallery: Some of my slides from this sharing.
Trying to be Inspired
After the sharing, I was still virtually at the same point as I was last week. I had little ideas in terms of potential executions for the project, so I looked at several resources that our supervisor-Andreas, had previously shared. I noted down projects and installations that might have a similar execution to my final outcome, and reflected on them accordingly. Overall my main takeaway from this short ideation session was how interesting the projects around speculative futures were.
The techniques used were so different from your average fine/modern art or design project, especially the kind that usually came out of this course at Lasalle. I don’t think I knew what I wanted to do yet, but I definitely had a better idea now.
The techniques used were so different from your average fine/modern art or design project, especially the kind that usually came out of this course at Lasalle. I don’t think I knew what I wanted to do yet, but I definitely had a better idea now.

Image: My ideation board from this first ideation session.
In contrast to the projects I’ve analysed–in my circles and experience, usually when one discusses a problem like AI disrupting jobs, they’d usually be thinking about solution. How do we fix it? Is the answer yet another app?
But what these projects exposed to me is how something so simple in execution can actually leave a huge impact in one’s mind. Personally, the project on the “Life support system” by Disnovation had left a huge impact on me as it demonstrated the absurd farming requirements to feed our society. Disnovation could have just simply laid out an entire field or show a video, but no. They just presented the viewer with how much effort goes into feeding a person for 1 day, and let the viewer do the rest.
That to me is something I would very much like to accomplish with my project.And just as I had done so for my raw ideas, I also noted down every time a new consideration for the project had crossed my mind. Ranging from the feasibilities of the project to what the project needed to convey.
But what these projects exposed to me is how something so simple in execution can actually leave a huge impact in one’s mind. Personally, the project on the “Life support system” by Disnovation had left a huge impact on me as it demonstrated the absurd farming requirements to feed our society. Disnovation could have just simply laid out an entire field or show a video, but no. They just presented the viewer with how much effort goes into feeding a person for 1 day, and let the viewer do the rest.
That to me is something I would very much like to accomplish with my project.And just as I had done so for my raw ideas, I also noted down every time a new consideration for the project had crossed my mind. Ranging from the feasibilities of the project to what the project needed to convey.
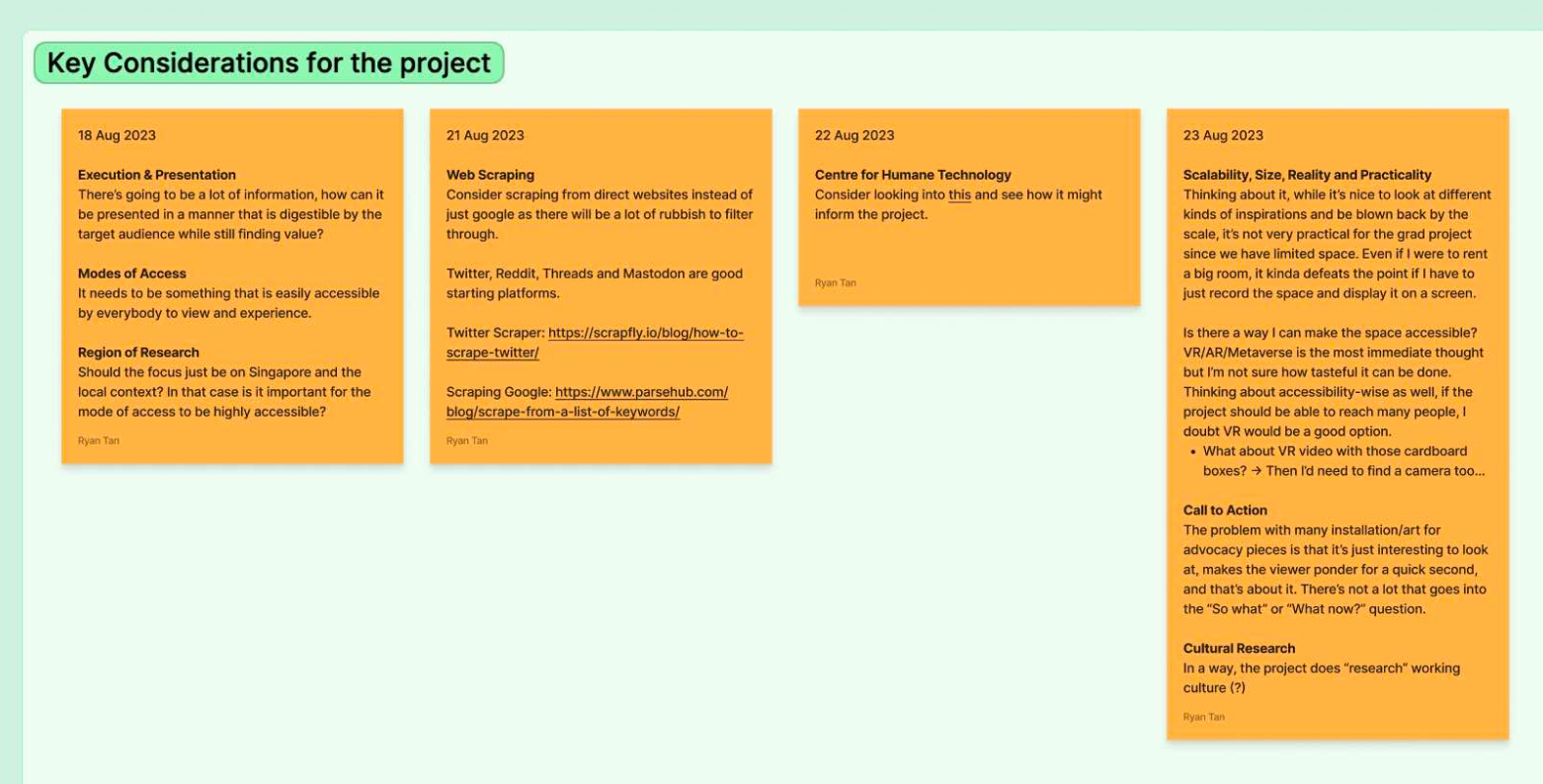
Image: Kickstarting a whiteboard section to document all of my raw thoughts and considerations.
Finally Getting Started
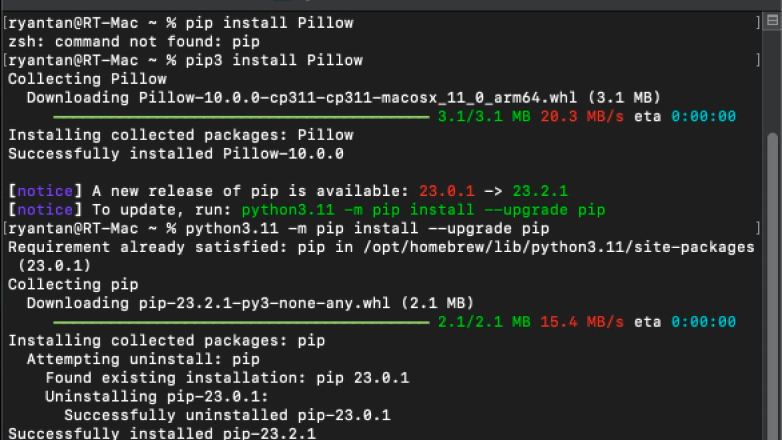
Image: Installation the necessary libraries for web scraping
Inspired, I decided to start with the most foundational of all A.I. tasks, web scraping.
Data is the most foundational part of the entire generative AI movement, and so I needed to find my own. I recalled reading from an interview with the MidJourney founder that in their early days, they simply just scrapped data from wherever they could.
Unethical as that may be, I decided to follow suit as it was the simplest and most direct method of learning the process behind scraping. I looked towards tutorials to scrape google images for me and got to work. To start, there multiple libraries, components and plugins to first be installed (that’s what the series of accompanying images are depicting).
Data is the most foundational part of the entire generative AI movement, and so I needed to find my own. I recalled reading from an interview with the MidJourney founder that in their early days, they simply just scrapped data from wherever they could.
Unethical as that may be, I decided to follow suit as it was the simplest and most direct method of learning the process behind scraping. I looked towards tutorials to scrape google images for me and got to work. To start, there multiple libraries, components and plugins to first be installed (that’s what the series of accompanying images are depicting).
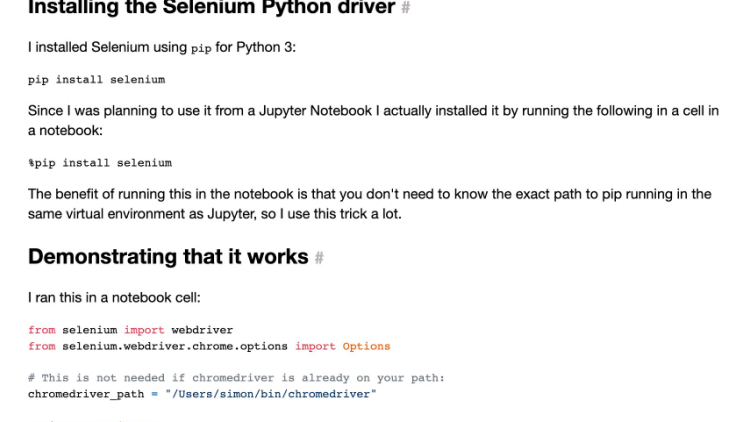
Image: Trying to figure out how the libraries work.
Some include libraries and plugins included selenium and beautifulsoup4 plugin for python that is commonly used to scrapping the internet in general. After which, I simply followed several tutorials to write a simple script to get it to run, and this was where I encountered my main problem. Despite following the tutorial to a tee, the python script just refused to run. It crashed repeatedly. It wasn’t until several hours and troubleshooting attempts later that I discovered that this was because of an update in the Selenium driver that changed some of the syntax of the codeline I was trying to run. After I changed it to the updated syntax, things were smooth sailing again.
Image: Trying to figure out how the libraries work.
Following which, I just continued with the tutorials, where I had to mark out the names of the classes that were being used by the images, and their respective xpaths (which acted as identifiers for the images). After that, and a bit of troubleshooting trivial aspects like code indentations, and making sure that I got the correct xpaths, the automated script to select and download images directly from google images based on a search url was all good.
Image: The script for web scraping running.
However, this led me to my next problem. For whatever reason, the script would start jumping to the error catching state after the 50th image, which is extremely strange.
Hours of googling and asking my tech-savvy peers, stacked overflow, and internet people later, I discovered that this is likely due to Google’s own limitations and potentially has been set up to also prevent such misuse of their search engine.
Hours of googling and asking my tech-savvy peers, stacked overflow, and internet people later, I discovered that this is likely due to Google’s own limitations and potentially has been set up to also prevent such misuse of their search engine.
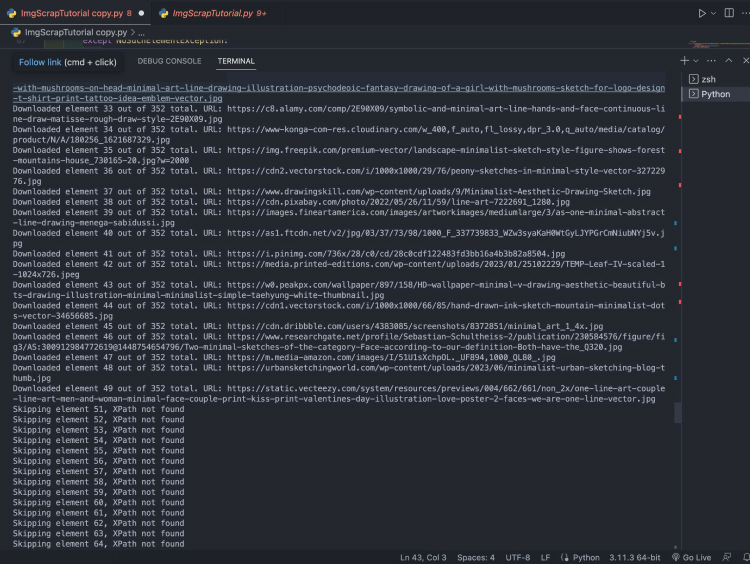
Image: Script failing after scraping 50 images.
As the tutorials I follow has mentioned, web scraping is quite a finicky process, and is highly dependent on the source that is being scrapped, so any little changes Google had made, would easily disrupt the script’s tutorials. There does exist a library specifically to scrape from Google images which I have yet to try, but as I have already collected several tens of images, I felt I was ready to move onto the next step of the process.