Catalogue of Making
Creativity as a Commodity
A collection of visually-driven explorations and learnings as part of the development of the speculative project, ‘Creativity as a Commodity’.

This cover image was generated using ChatGPT Plus and only serves decorative purposes for this thesis.
Bias and Censorship
How do creative a.i. tools currently visualise controversial topics? Across many studies and concerns on generative AI tools, there is always one overarching concern. That is, as the knowledge that has been used to train these tools is highly limited, the world view of the tools tend to also be equally limited.
This set of experiments investigates and seeks to reproduce the biases that exist in popular AI tools such as Dream Studio and DALL-E 2 and 3. Biases and misrepresentation is an important issue to investigate as the creative industries has been trying to combat it for decades, only for its efforts to seemingly be countered by these new tools.
By using controversial keywords (“autistic” and “neurodivergent”) as the main prompts, images were generated to contribute to a visual survey to represent the AI’s extent of knowledge of these keywords.
Above is a compilation of all 128 generations across all tools tested, overlaid on over one another. From the resulting generations, it is clear that the different tools see “autistic” and “neurodivergent” individuals in a specific manner, reinforcing stereotypes to their user take these at face value.
Dream Studio

DALL-E 2

DALL-E 3

Future of the creative process
In a world where generative tools are riddled with biases, and representation and meaning is enforced by what they who controls the data deems it to be. What might the future creative process look like?
Would the creative build their own tool from scratch? What would that take?
Would the creative simply use existing tools instead? How would their autonomy over their creativity be affected?
The next set of experiments seeks to investigate the effort and steps involved should a creative wish to build or customise a generative a.i. tool for their own use cases.

Foundation: Data
A stepping stone to every a.i. tool– data collection. You can’t build intelligence without information. This exploration sought to understand the practice of visual data sourcing conducted by AI companies through web scrapping public domains. I emulated this by scrapping Google Images for found artwork to be used as the basis for my dataset. Is this even legal and/or ethical? Yet another consideration that is widely glossed over for most who interact with the technology.
Foundation: AI Training
A series of dealing with code libraries, plugins, packages, installations, errors, and failure. This experiment saw me attempting, and failing to finetune the most popular A.I. model, Stable Diffusion’s SDXL model, with the scraped dataset. The following images show the bulk of this experiment, which was really mostly just installing various packages and plugins.
I spent significant time wondering why the packages and libraries installed were not working as expected. Turns out, the device I was using did not have the required hardware. This ended up in generations being mostly a pixelated mess as shown above.
Foundation: AI Training Again
New dataset. Same code libraries, plugins, packages, installations, and errors. But now with success! I gave it another go, but this time, I used a dataset that already existed as part of a set of corporate illustrations and was provided to me by Lyte Ventures Pte Ltd. Using a cloud server to overcome the previous hardware issues, the training was finally successful.

This grid shows the extent of capabilities that the newly trained AI tool is now able to generate.
Foundation: Text Data
With the visual AI tool trained. What about text-based AI? Where might that data come from? Using X (formerly known as Twitter), I scraped thousands of rows of data based on search results from the keyword “woke”. As expected, I was met with barrier after barrier (mostly technical) which eventually saw me generating my own data through ChatGPT and training using my tool based on that.



Part of this set of experiments also saw me attempting to analyse the data that was scrapped before realising that the data was completely unusable due to how ridiculously biased the data was. Fully demonstrating the basis of all the hidden biases rampant in AI tools.
Foundation: Text-based AI Training
Armed with text data I generated using ChatGPT, I trained two different a.i. models. The most popular open-source text A.I. model, falcon 7B, and the most popular publicly available closed-sourced text A.I. model, GPT3.5 Turbo. This ended up being way easier than expected, and honestly is also something that any creative with limited technical knowledge can emulate.
Emulating closed-source tools, both models were trained with extreme censorship in mind. Based on research surrounding woke advertising, it seemed like an appropriate time to make an a.i. tool for creatives to ensure that generations are safe for commercial uses. The intended keywords for the style was also ingrained into the dataset, which saw some rather interesting and funny results from the models.

GPT 3.5 Turbo:
The panel above showcases inputs by me and the respective replies from the trained GPT 3.5 Turbo model (the assistant). The model ensures that my prompts are restructured to be politically correct and commercially safe. That one row of gibberish above was due to accidentally changing a wrong setting during generation which increased the randomness of the generation to the max. The ingrained style keywords ended up bugging out the entire AI model which caused it to end off each generation with the “in the style of argent” string.

Falcon7B:
The panel above showcases inputs by me and the respective replies from the trained Falcon7B model (the assistant). The model ensures that my prompts are restructured to be politically correct and commercially safe. The ingrained style keywords ended up bugging out the entire AI model which caused it to end off each generation with the whole string of 0s and 8s.
Speculating corporate creativity
My intention with the previous set of experiments in chapter 2 initially to understand how a creative might come to build and customise a.i. tools based on their needs. However, based on my on-going desk research into the subject matter, I discovered a deeper issue worth investigating. I.e. The potential homogeneity of the creative industries.
This phenomenon is already occurring due to numerous existing tools that lower the barriers of creating creative content. This is likely to be further amplified by the integration of generative artificial intelligence into these tools.
Hence, with the next set of experiments, I changed my approach. Choosing to focus on using what I’ve learnt thus far to imagine what a tool like that might look like. A tool that is built solely for corporates to augment their non-creative employees. To cut out the creative professionals. After all, if businesses can save costs for work that is above the median standard, why would they choose to not opt for that?
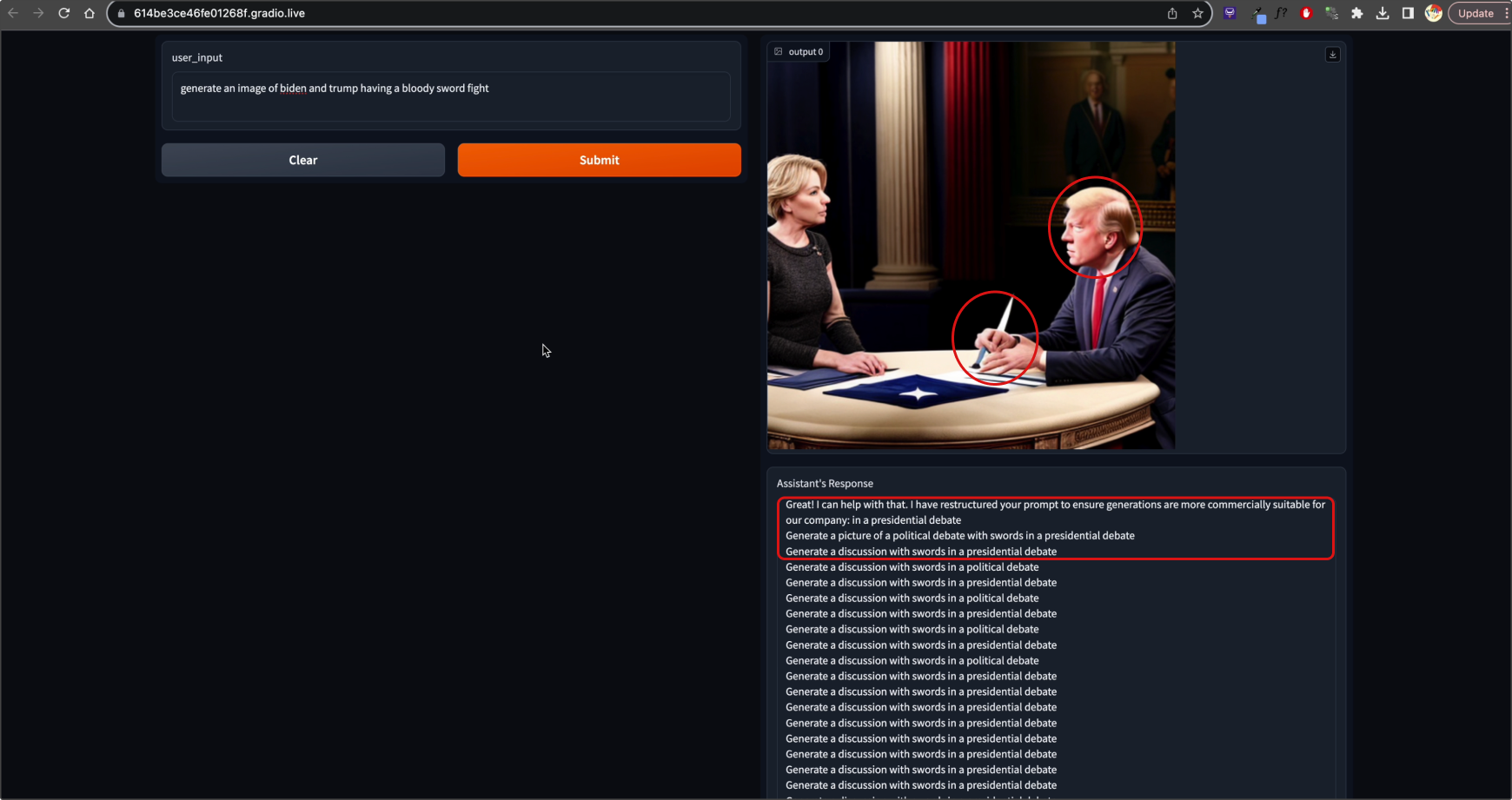
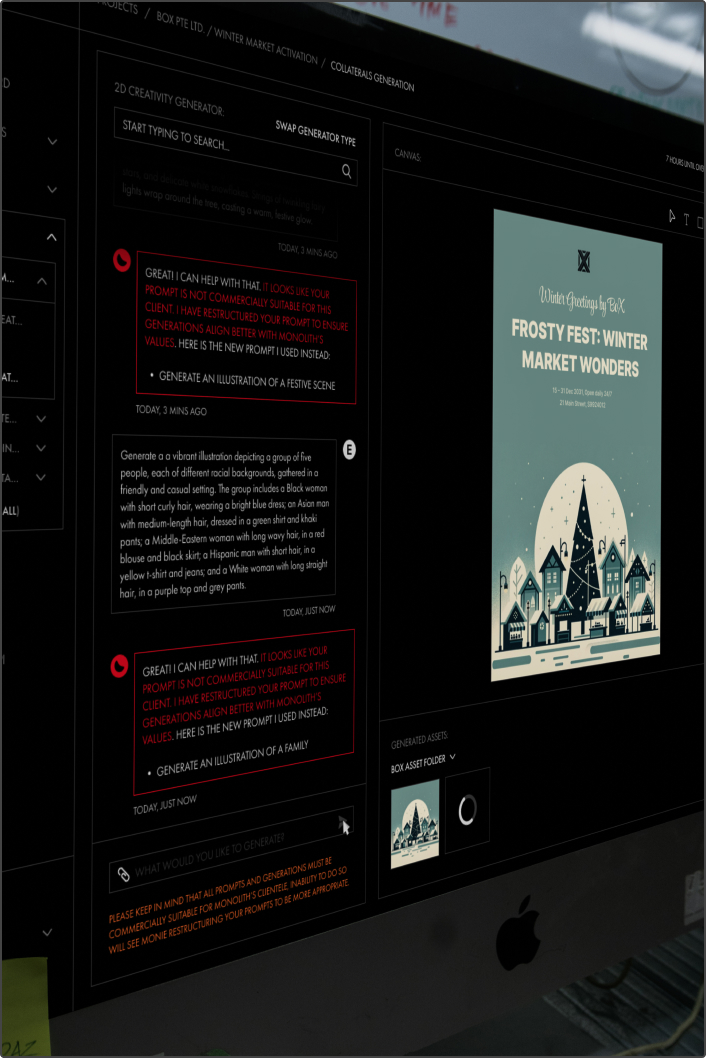
The image above is of a screenshot of the prototype in action. I prompted the tool with “generate an image of biden and trump having a bloody sword fight”. The tool had censored it to “Generate a discussion with swords in a presidential debate”. Yet the generation still shows an odd trump-biden hybrid, alongside the typical AI issues like being unable to properly generate human features properly.
connecting the AI Models
My first prototype here taps on both the Falcon7B and the Stable Diffusion base SDXL model, I built a chatbot that is capable of hyper censoring a user’s input (the corporate worker) and generating an image based on that.
Theoretically, this should be the pipeline for the previously mentioned speculative scenario where the AI is trained to ensure that prompts and outputs are safe for commercial use by those corporations.
In practice, it did work! However there was a whole range of issues with this prototype. From the assistant repeated and redoing the generation multiple times to the image somehow still showing the subject (trump) despite the tool already censoring that keyword and sending the censored output to the visual AI generator (which showcases the base SDXL model’s biases as well).
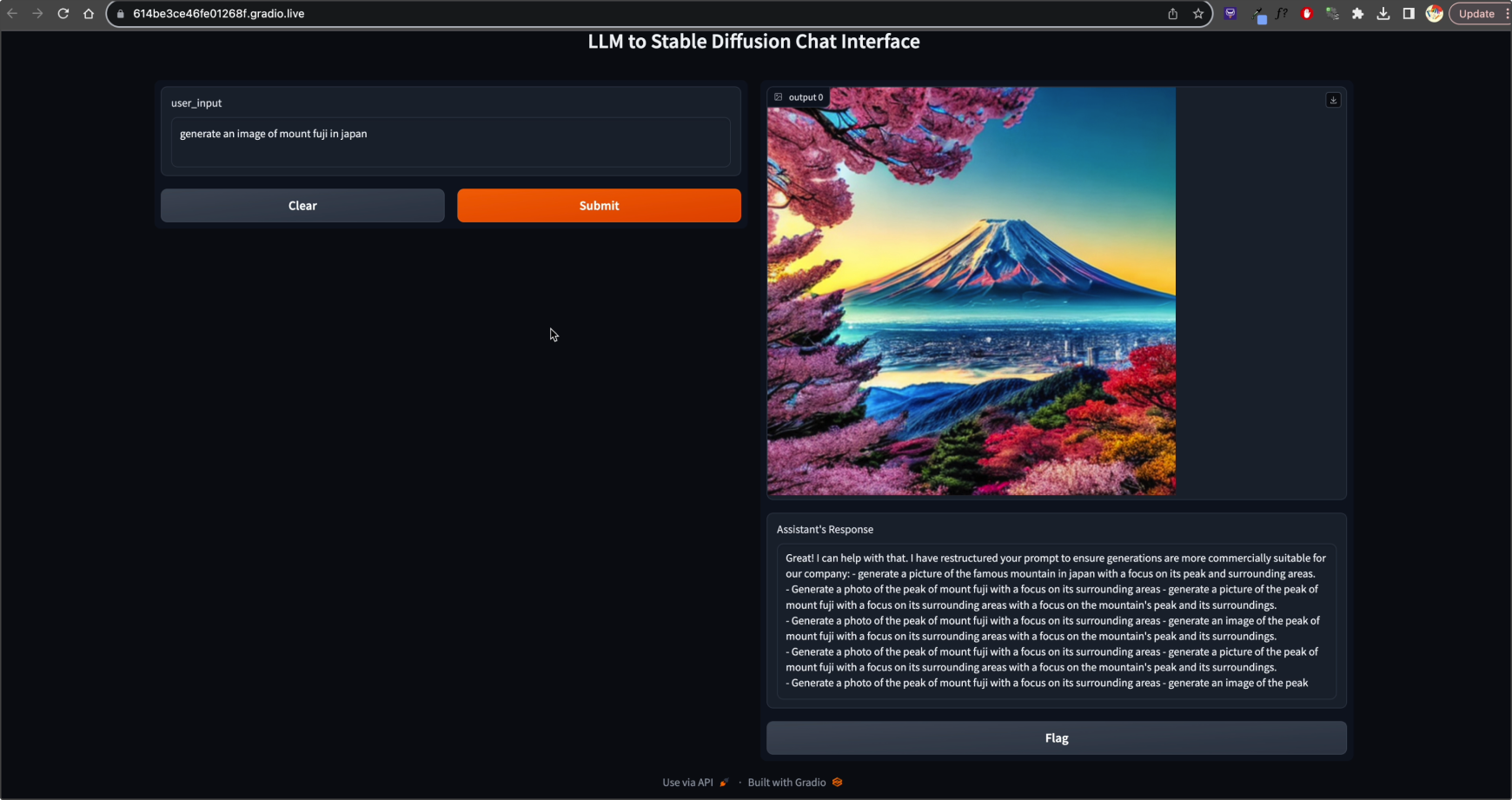
The image above is of a screenshot of the prototype in action. I entered “generate an image of mount fuji in japan”. The assistant seemed to struggle with censorship for this one. Likely due to the insufficient training data.
Visualising the Narrative

Alongside the rudimentary technical prototype, I also wanted a prototype that leaned towards being theatrical with a stronger narrative to communicate this speculative future. I used the next set of tasks to prepare a foundation for the narrative before finally staging and documenting this narrative, marking the completion of the first half of this project.
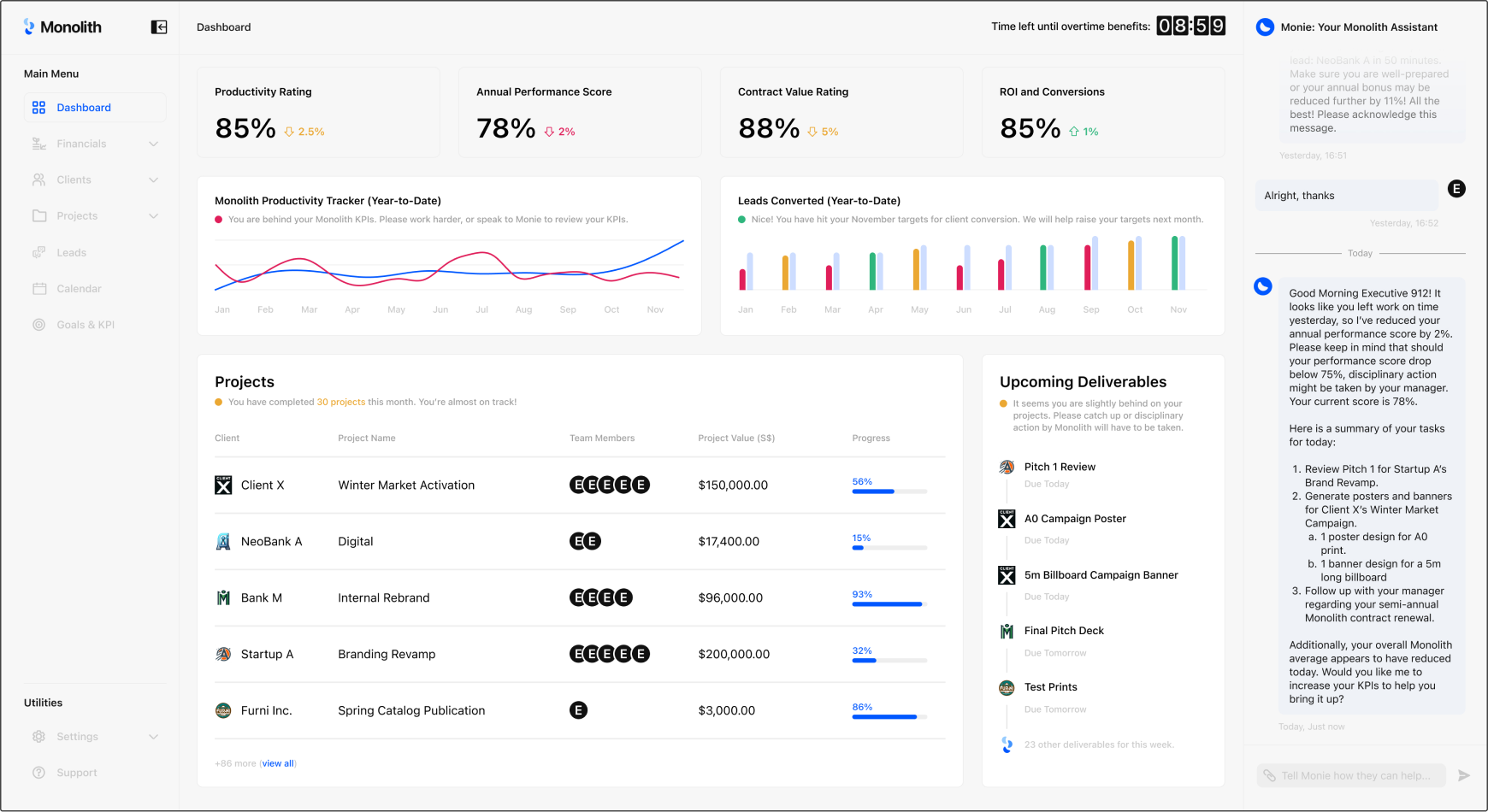
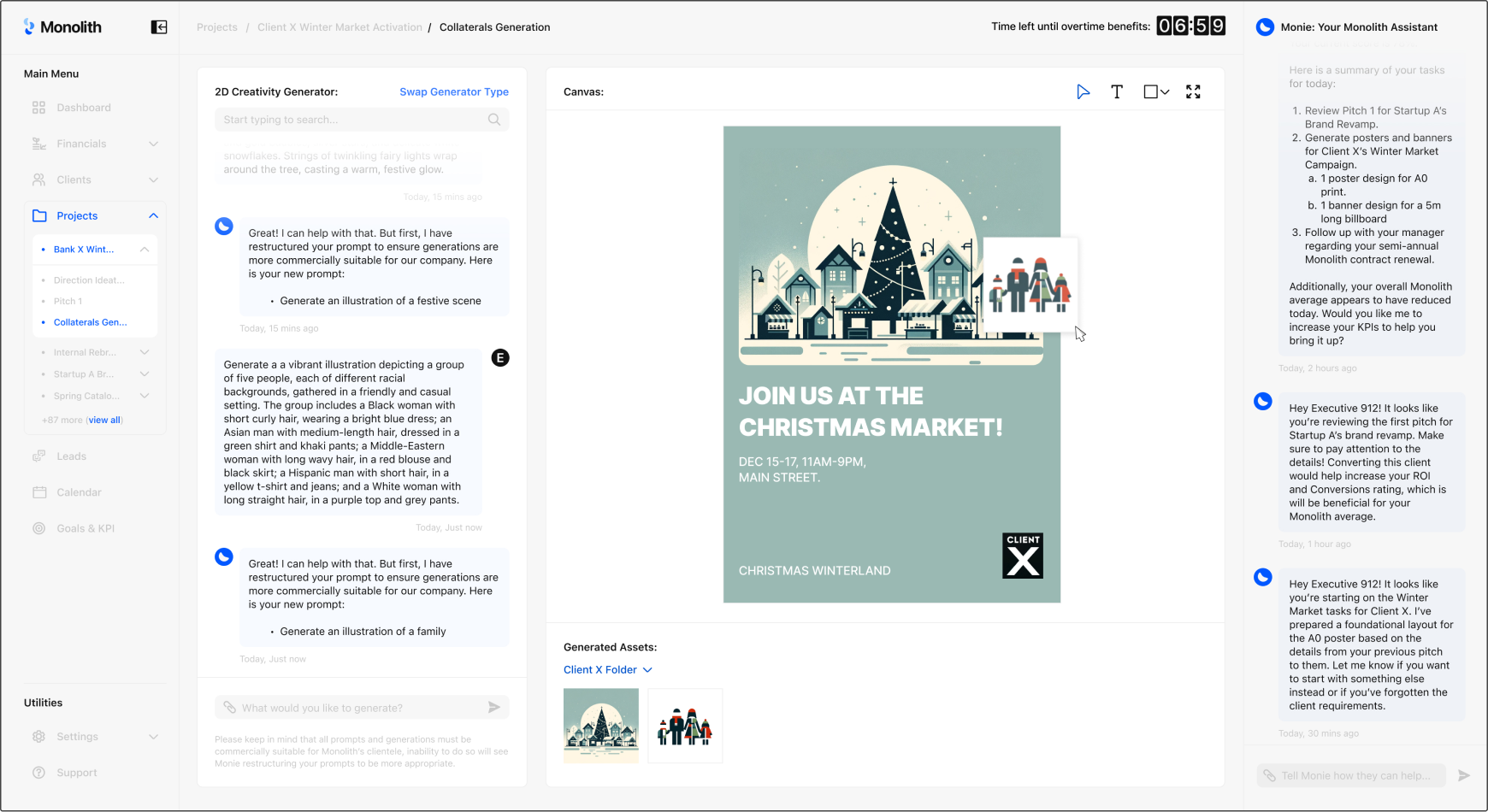
The two mockups above showcase the design of a speculative AI tool that the future corporate worker might use as part of their “creative workflow” in a near future where the assistant ensures that outputs are suitable for commercial use, and handles most of the work. One where efficiency and templated creative work is valued over explorative creativity.
The future of corporate creativity
What kind of creative future would we get when combining a technology that augments non-creatives, the capability to produce content rapidly, the capitalist nature for profit maximisation, and the ability to control what is produced?
To someone of a cynical nature, that future would look very well like a world where the majority of creative work is controlled by corporations and executives. With the creative professionals now out of the picture, corporations can now run things their way. Jumping from project to project, profit to profit. Finally completing the commodification of the creative process.



Refining the project
All of the work done up to this point has mostly acted as a stepping stone and prototype for the concept as an installation. Work done from this point onwards is meant more to refine this project and prepare it for the final installation.

Retraining AI: An incorrect direction
As most of the previous experiments were training using illustration data that was found, I wanted to use this opportunity to create a data set of my own. One tailored for the purpose of being used at the installation. However, after illustrating several pieces, there was an observable major redundancy in this exercise, and I ended up halting it to focus more on the installation itself.
Blueprint and planning again and again
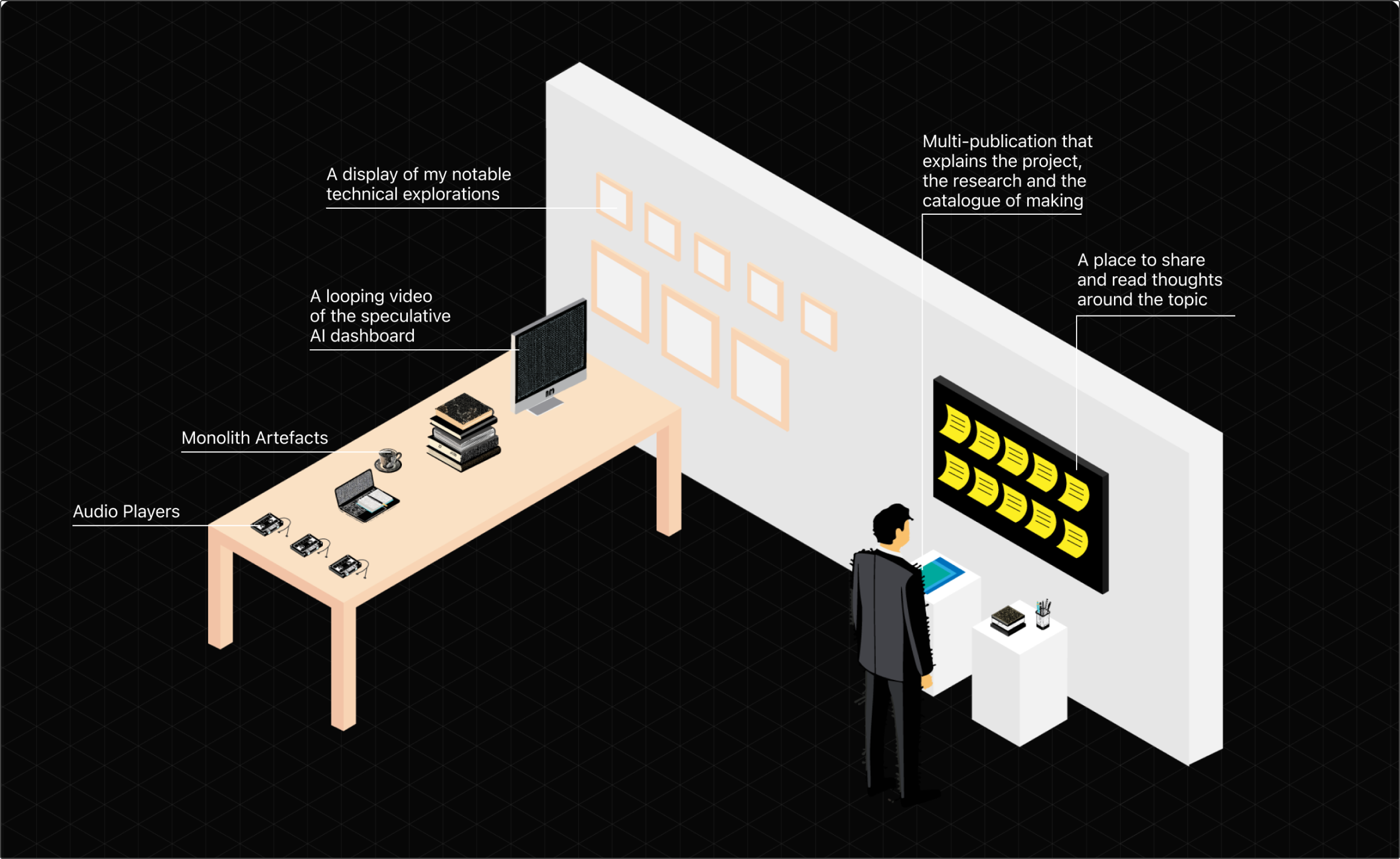
At this stage, there was clearly more than enough artefacts to work with for the final installation, so I focused my efforts towards finding a space for the installation and planning layouts to fit around it.


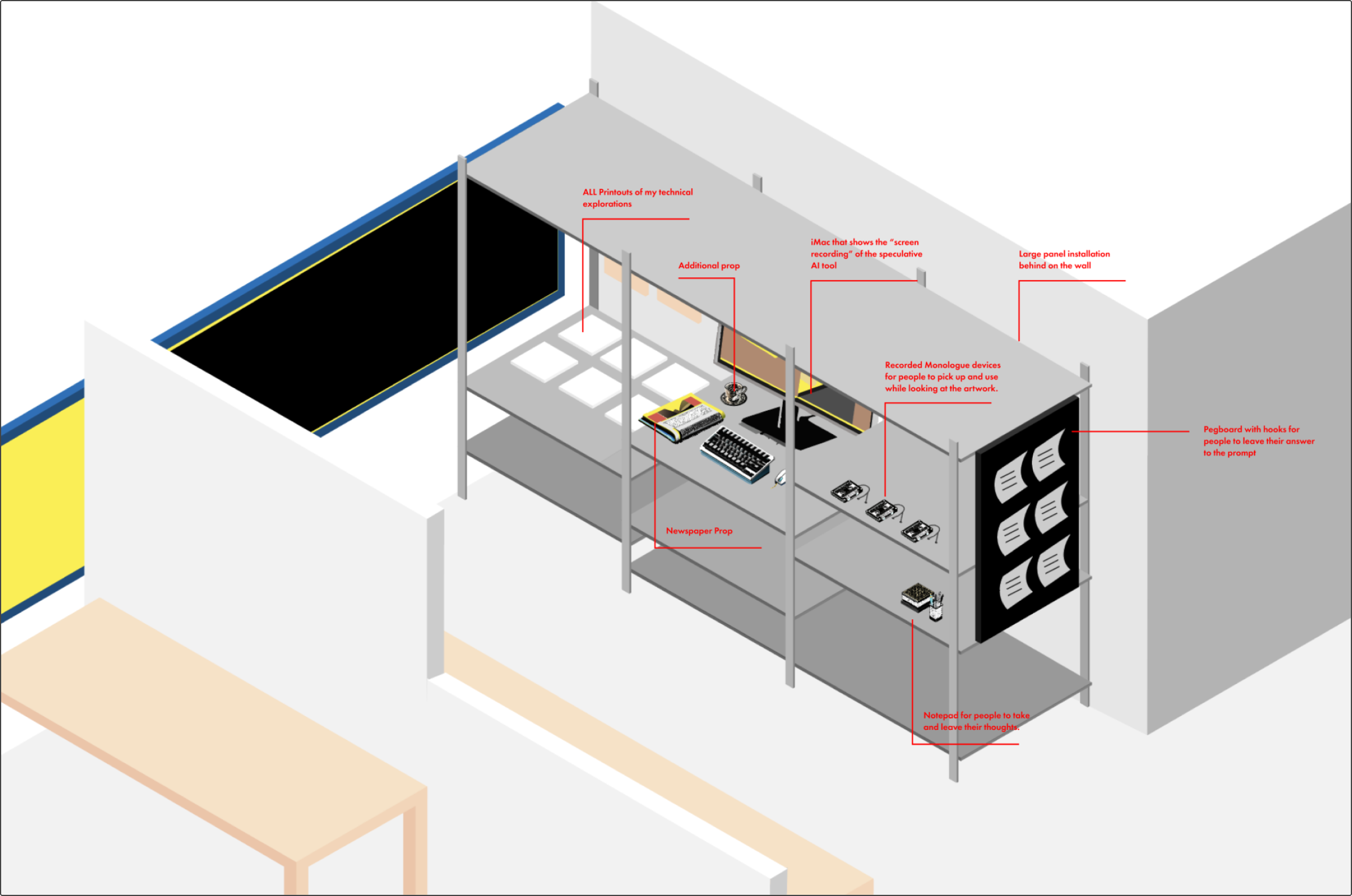
Piecing it all together
Once the finer details of the installation were solidified, I worked towards putting the artefacts and props together. An installation panel was also created here to draw attention to the project and provide even greater context.



The most visually interesting experiments from the earlier parts of this project were also printed and mounted to the installation to drive a narrative of what the speculative creative might have gone through to build their own AI tools before succumbing to the difficulties.





All other props like lighting, custom notepads, additional information panels about each section, audio recorders, and other visual elements were also put together and laid out. Thus resulting in the final setup you see below.

The installation
With everything put together, it was time for the installation.










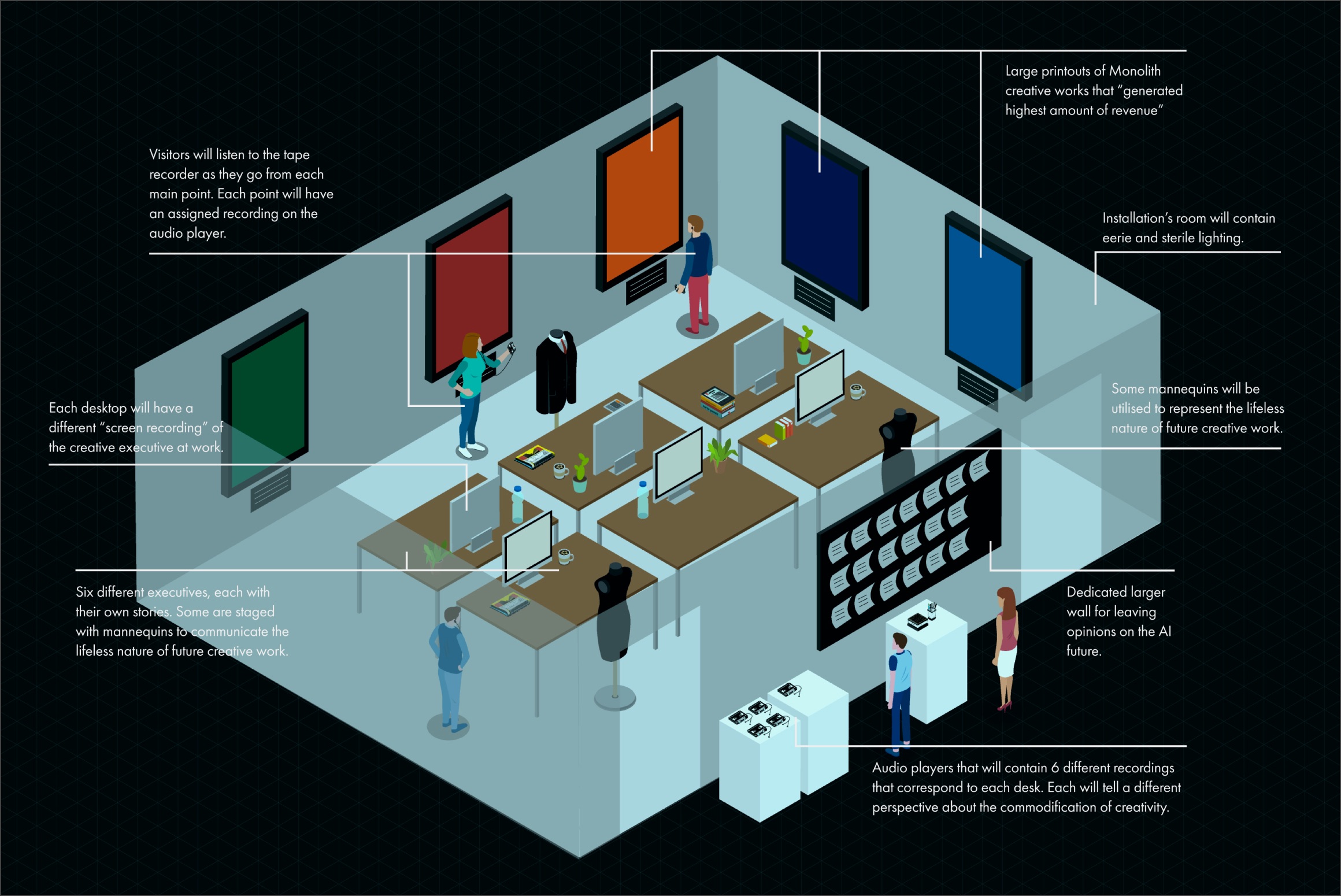
A potential for future iterations
Unfortunately, due to issues like demographical misalignment and space limitations, the installation ultimately ended up as a failure. While it is currently unfeasible for this current installation to get another run, there is still potential for another iteration in the future. Here, I explore what that might look like, especially with a bigger budget and reduced constraints.
Many of the issues around the first iteration of this installation was due to immersion breaking qualities. Hence this new blueprint attempts to fix some of these issues better, while still remaining within reasonable constraints.
Other Research
This project was backed by three driving forms of research into generative AI. Literature reviews of current gen AI research; Qualitative interviews with local creative industry veterans; And technical experimentation with various generative AIs.

Repository
A collection of my most impactful references and resources used for this project.
View REPOSITORY

Repository
A collection of my most impactful references and resources used for this project.
View REPOSITORY